23. AWS監視リファレンス
本書はX-MONを用いてAmazon Web Service (以下AWS) の各種サービス、リソース、インスタンスを監視するためのリファレンスとなっております。
基本的なAWSの操作方法や用語、またX-MONについての知識についてはご理解の上でお読みください。
また、AWSの操作画面は本書記載時の情報であり、変更となっている場合がございます。
23.1. はじめに
本書では、AWSの各種サービス、リソース、インスタンスを監視するためのX-MONの操作方法を解説します。
対応している監視項目は
EC2
ELB (ALB, CLB)
RDS
S3
課金状態監視
AWSカスタムメトリックス監視
となっております。
AWSで提供されている監視サービスであるCloudWatchから値を取得し、X-MONで監視を行います。
そのため、X-MONから CloudWatch のエンドポイントへアクセス出来る必要があります。
CloudWatchでは値を15か月しか保持する事は出来ませんが、X-MONで監視を行うことで2年間値を保持する事が出来ます。
23.1.1. AWS監視に必要な情報について
AWS監視を行うためには以下の情報が必要となります。
AWSアクセスキー
AWSシークレットキー
リージョン
インスタンスID (監視内容による)
AWSアクセスキーとAWSシークレットキーは、AWSにログインの上ご確認くださいますよう、お願いいたします。
取得には、CloudWatchの「Read」権限が必要となります。
AWSのIAM設定より、「CloudWatch Read Only Access」で設定可能です。
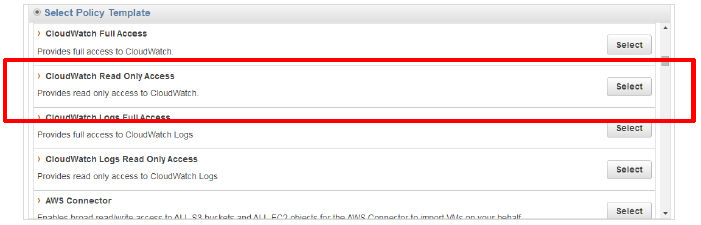
※RDSのログ監視を行う際は「Power User Access」もしくはIAMに以下権限の割り当てをお願いします。

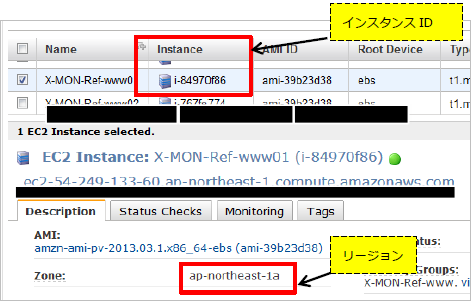
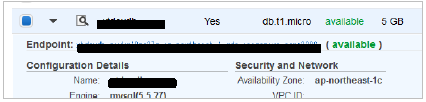
リージョンとインスタンスIDは監視対象のインスタンスの詳細画面でご確認頂けます。
ZONEの部分がリージョンとなっております。
23.1.2. ホストの登録方法
必要な情報が集まったらホストの登録を行います。
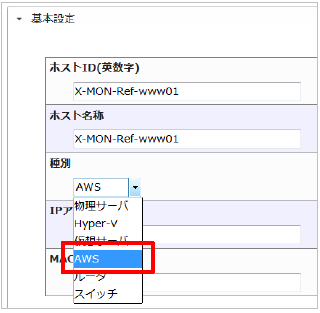
ホスト登録では、基本設定の種別で「AWS」が選択出来ますので、AWSを選択します。
また、「AWS設定」のタブがありますので、 AWS監視に必要な情報について にて取得した情報を入力してください。
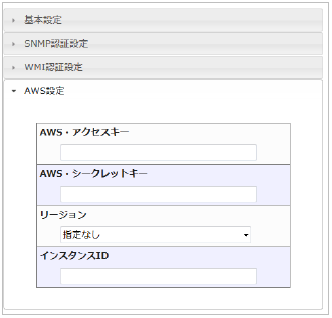
23.1.3. FQDNについて
X-MON3.0.8以降では、ホスト登録に FQDN が使用出来るようになりました。 インターネット経由でX-MONからAWS環境の監視を行う場合、FQDNを使用する事によりAWS環境の実IPアドレスの動的な変更にも対応する事が可能となります。
EC2インスタンス、ELBに対しHTTP監視などのサービス監視を行う際はFQDNでホストの登録をお願いします
23.1.4. IPアドレスについて
AWSにおいて、EC2ではグローバル固定IPアドレス(Elastic IP address)を設定出来ますが、RDSとELB、S3についてはグローバル固定IPを設定する事が出来ません。
※ RDSはPublicly Accessibleオプションを使用すれば可能です
そのため、RDS、ELBのホスト登録の際のIPアドレスについて2パターンと、check_dummyプラグインを使用する1パターンをご用意しておりますので環境に合わせてご使用ください。
X-MON3.0.8以降ではホストの登録にFQDNを使用する事が可能です。
23.1.4.1. ローカルホストのIPアドレスを使用する
ホスト登録にてローカルホスト(127.0.0.1)のIPアドレスを使って登録します。
こうする事によりデフォルトで動作するホストのオンデマンドチェックに対しても対応する事が出来ます。
本書のRDSとELBはローカルホストのIPアドレスを使用してホストを登録しております。
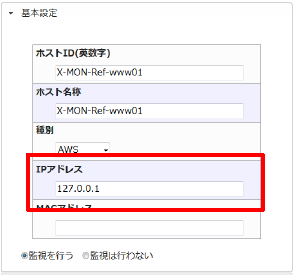
「AWS設定」のタブ内の情報も忘れずに記入してください。
23.1.4.2. 内部のローカルIPアドレスを使用する
RDSとELBは内部のローカルIPアドレスを持っています。 しかし、通常のEC2内のローカルIPアドレス、また作成したVPC環境内のローカルIPアドレスであってもping応答を得る事が出来ません。 そのため、内部のローカルIPアドレスを使用する際はホストのアクティブチェックを無効にしてホストを登録します。
設定例では、IPアドレスを10.122.10.1のローカルIPで登録します。
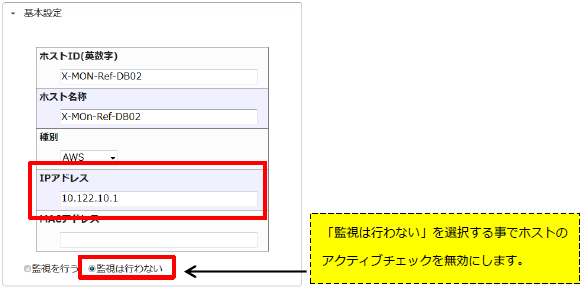
「AWS設定」のタブ内の情報も忘れずに記入してください。
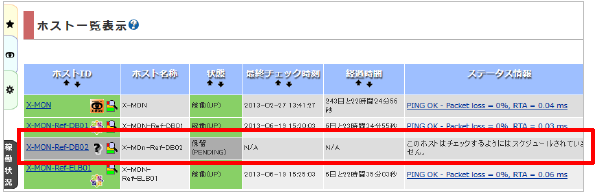
ホストのアクティブチェックが無効の場合、ホスト一覧の画面では下記のように「このホストはチェックするようにはスケジュールされていません。」と表示されます。サービス監視を設定しOKを検知しても、ホストのチェックはされません。
なお、AWSではRDS、ELBはEndpointURL、またはドメインを使用してのアクセスを推奨しております。 AWS内にて動的にIPアドレスが変更になる、またフェールオーバーの際に通信を維持するためです。
ここで設定したIPアドレスは変更される場合がございますのでご注意ください。
X-MON でのホスト情報登録においても内部のローカルIPアドレスではなく、 FQDN での指定を推奨いたします。
23.1.4.2.1. RDSのIPアドレスを調べる
RDSのIPアドレスを調べるにはEndpointURLからポート番号を除いたアドレスをEC2インスタンス上にて名前解決を行います。
EndPointURLが「xmonrefdb.caykgj0ns37z.ap-northeast-1.rds.amazonaws.com」の場合、EC2(Linux)にて下記コマンドで確認します。
$ dig xmonrefdb.caykgj0ns37z.ap-northeast-1.rds.amazonaws.com |
~中略~
;; ANSWER SECTION:
xmonrefdb.caykgj0ns37z.ap-northeast-1.rds.amazonaws.com. 60 IN CNAME ec2-54-249-144-85.ap-northeast-1.compute.amazonaws.com.
ec2-54-249-144-85.ap-northeast-1.compute.amazonaws.com. 60 IN A 10.122.10.1
~中略~
EC2インスタンスにてWindows系OSを利用されている場合は、コマンドプロンプトからnslookupコマンドを実行することで同様にご確認頂けます。
23.1.4.2.2. ELBのIPアドレスを調べる
HTTPの負荷分散をしている場合はEC2インスタンス上のアクセスログにてご確認頂けます。
$ sudo less /var/log/httpd/access_log |
CLB の場合、アクセスログに「"ELB-HealthChecker/1.0"」とあるのがCLBからのアクセスになりますので、このアクセス元IPアドレスがCLBの内部ローカルIPアドレスとなります。
ALB の場合、アクセスログに「"ELB-HealthChecker/2.0"」とあるのが ALB からのアクセスになりますので、このアクセス元IPアドレスがALBの内部ローカルIPアドレスとなります。
23.1.4.3. check_dummyを使用する
check_dummyプラグインを使用すると、ping疎通が出来ないホストに常に同じステータス状態を指定出来ます。今回の場合では常にOKを返すような設定を行いますが、ホストダウンは検知が出来ませんのでご了承ください。
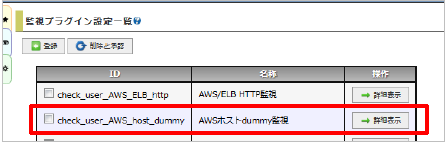
23.1.4.3.1. ホスト用独自プラグイン設定を作成する
check_dummyプラグインを使用してホスト用の独自プラグイン設定を作成します。
X-MONの[高度な設定]の[監視プラグイン設定]より行います。
登録をクリックします。
新規登録画面となります。
設定例を記載しておりますので、その通り記入してください。
項目 |
内容 |
|---|---|
コマンドID(英数字) |
AWS_host_dummy |
コマンド名称 |
AWSホストdummy監視 |
コマンドタイプ |
ホスト用コマンド |
コマンドグループ |
死活監視 |
実行コマンド |
check_dummy |
引数 |
$ARG1$ $ARG2$ |
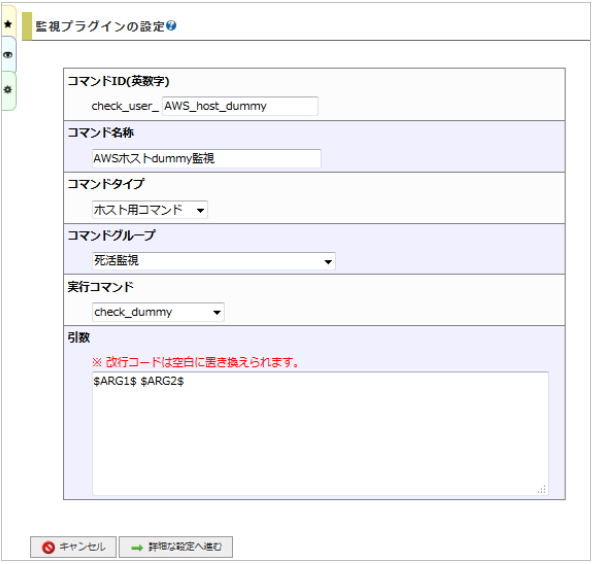
入力が出来たら「詳細な設定へ進む」をクリックします。
引数に対する入力設定(監視設定時に表示される項目名やデフォルト値)を設定しますので下記表の通りに設定します。
引数 |
項目名 |
デフォルト値 |
|---|---|---|
$ARG1$ |
状態指定。
0(OK),1(WARNING),2(CRITICAL),3(UNKNOWN)
|
0 |
$ARG2$ |
応答文字列 |
(入力なし) |
状態指定では、常にOKを返す0をデフォルト値としておきます。
1だとWARNING、2だとCRITICAL、3ではUNKNOWNを返します。
応答文字列はステータス情報欄に表示される文字列を指定出来ます。
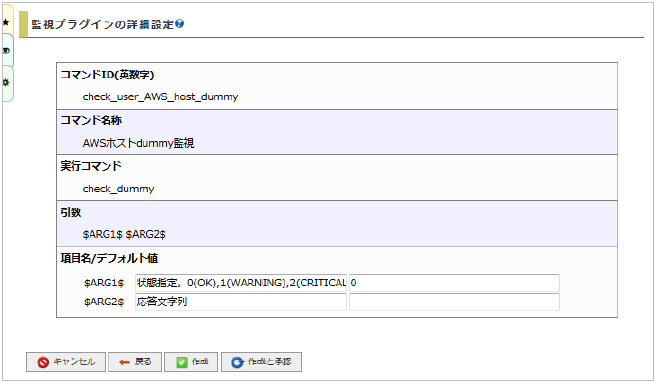
入力が出来たら「作成と承認」をクリックして完了してください。
23.1.4.3.2. ホストの登録例
ホストを登録する際は任意のIPアドレスを指定します。
今回はping疎通の出来ないRDSの内部のローカルIPアドレスを使用します。
調べ方は RDSのIPアドレスを調べる をご参照ください。
設定例では、IPアドレスを10.122.10.1のローカルIPで登録します。
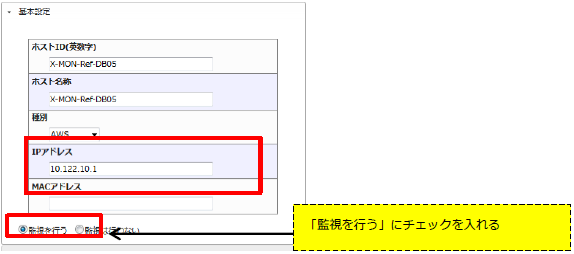
「AWS設定」のタブ内の情報も忘れずに記入してください。
[詳細な設定へ進む]をクリックします。
[ホスト監視用コマンド]がありますので、デフォルトの「PING監視(ホスト用)」を先ほど作成した「AWSホストdummy用」に変更します。
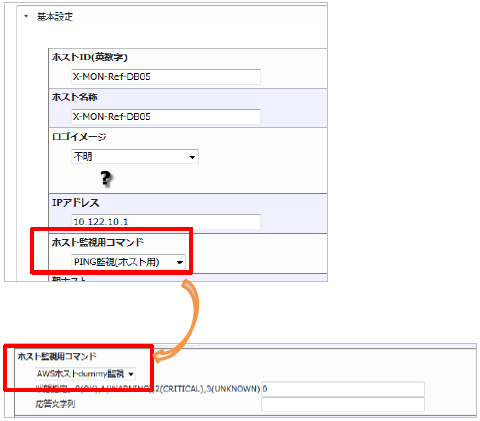
今回は応答文字列に「RDSインスタンスのためping応答なし」を入力します。

次に「高度な設定」タブ内の[フレッシュネスチェック]が「無効にする」(デフォルト)である事を確認します。
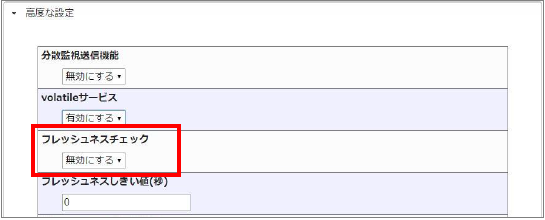
確認が出来れば[作成と承認]をクリックして作成を完了してください。
作成後、ホスト一覧ではアクティブチェックが無効の時と同じように「このホストはチェックするようにスケジュールされていません。」と表示されます。

作成が出来れば、ホストに対して通常のサービス監視を設定します。
サービスがOKを検知すると、ホストの状態がOKとなります。

ステータス情報欄に、ホスト登録の際に指定した文字列である「RDSインスタンスのためping応答なし」が表示されます。
以上でcheck_dummyプラグインを用いたホスト登録は完了です。
23.1.5. 粒度について
AWSの監視では、監視コマンドの設定に「粒度(秒)」項目の設定が存在します。
プラグインが実行された際、現在の値を取得しに行くわけではなく、蓄積された値より指定された粒度分毎に、平均、最大、最小を計算して値を取得します。
つまり、平均値、最大値、最小値を計算する期間を指定するのが粒度となります。
以下、粒度:300(秒)の場合の計算期間です。
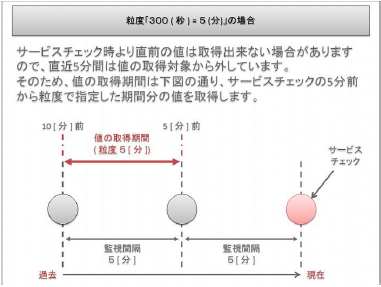
本書ではデフォルトの300にて監視設定例を記載します。
値が正常に取得出来ない場合は指定した粒度の間隔には値が入っていない可能性がありますので、粒度の値を大きくして(600等)値が取得出来るかを一度ご確認ください。
23.1.6. 監視閾値の値について
AWS 監視では、閾値にデフォルトの値を設定しておりません。
作成するインスタンスに自由にリソースの割り当てが出来るクラウド環境の監視においては、インスタンスに割り当てたリソースによって適当な閾値が変わるためです。
監視設定時には、CloudWatch のグラフ画面等にてリソースの推移を確認しながら閾値を設定してください。
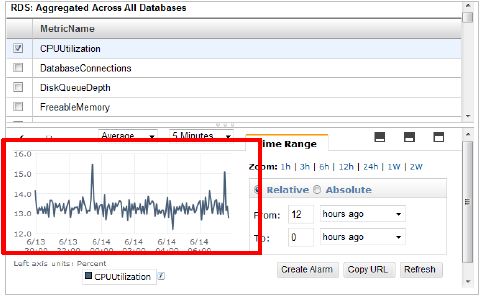
23.1.7. 監視閾値の設定方法について
AWS監視では、閾値の設定方法(入力方法)が他の監視とは異なります。
上限(閾値以上の値の場合に障害を検知する)と下限(閾値以下の値の場合に障害を検知する)を設定できます。
設定は「:」(コロン)を使用します。
閾値の前に「:」を入れることで、閾値以上の場合に検知するように設定出来ます。
例えばCPU使用率(%)を監視するにおいて、値が80%を超えたとき (値 >= 80) に監視ステータスをWARNINGにする場合は「80」または「:80」と指定します。
閾値の後に「:」を入れることで、閾値以下の場合に検知するように設定できます。
例えばELB有効インスタンス数監視を監視するにおいて、有効なインスタンス数が2を下回ったとき (値 <= 2) に監視ステータスをWARNINGにする場合は「2:」と指定します。
範囲指定を行うことも可能です。「20:80」とすると、値が20を下回った際、もしくは80を上回った際 (値 <= 20 または 80 <= 値) に異常を検知します。
なお、閾値を入力しない(空白)の場合は閾値の判定を行いません。
23.2. AWS EC2監視
AWS EC2監視の監視方法について解説します。
ホストの登録方法は ホストの登録方法 をご参照ください。
HTTP監視等のサービス監視を行う際はホストをFQDNで登録してください。
本章ではホスト名を「X-MON-Ref-www01」で登録し、粒度はデフォルトの300を使用します。
23.2.1. 共通警告パターン
EC2監視ではCRITICAL、WARNING、UNKNOWNが警告パターンとなっております。
ステータス |
内容 |
|---|---|
CRITICAL |
・APIのリクエストが送信できなかった場合
・データの取得に失敗した場合
・CRITICALのしきい値判定の結果
|
WARNING |
・WARNINGのしきい値判定の結果 |
UNKNOWN |
・APIのデータ通信は成功しているが、適切な値が取得できなかった場合 |
また、監視設定を行う前に、前提として
をご確認ください。
23.2.2. EC2 CPU使用率監視
監視グループ |
チェックコマンド |
|---|---|
AWS EC2 |
AWS/EC2 CPU使用率監視 |
EC2インスタンスのCPU使用率を監視します。
CloudWatchで確認できるMetric/CPUUtilizationの値で、指定した粒度での平均値が取得されます。
・監視設定例
CPU使用率が30%を超えるとWARNING、50%を超えるとCRITICALを検知するようにするには以下のように設定します。
■ 監視設定例
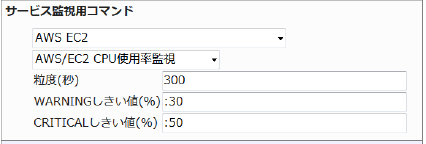
正常に監視できると以下の画像のようにステータス情報欄にCPU使用率が表示されます。CPU使用率が高いと、アクセスが多く負荷が高くなっているなどの可能性があります。

23.2.3. EC2 DISK書込回数監視
監視グループ |
チェックコマンド |
|---|---|
AWS EC2 |
AWS/EC2 DISK書込回数監視 |
EC2インスタンスのディスクの書き込み回数を監視します。
CloudWatchで確認できるMetric/DiskWriteOpsの値で、指定した粒度での平均値が取得されます。
・監視設定例
書き込み回数の平均(粒度300なので5分)が100を超えるとWARNING、200を超えるとCRITICALを検知するには以下のように設定します。
■ 監視設定例
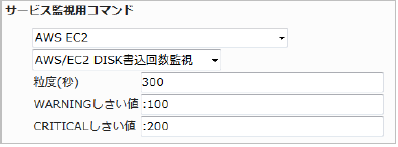
正常に監視が出来ると以下の画像のようにステータス情報欄に「書き込みディスク回数: ○ Count」(○は数字)が表示されます。ディスクの書き込み回数が多いと、アクセスが多く負荷が高くなっているなどの可能性があります。

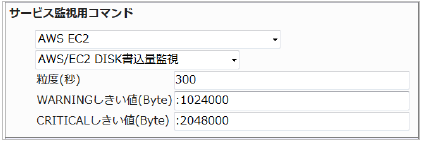
23.2.4. EC2 DISK書込量監視
監視グループ |
チェックコマンド |
|---|---|
AWS EC2 |
AWS/EC2 DISK書込量監視 |
EC2インスタンスのディスクの書き込み量を監視します。
CloudWatchで確認できるMetric/DiskWriteBytesの値で、指定した粒度での平均値が取得されます。
・監視設定例
単位がByteのため、数字が大きくなりますのでご注意ください。
書き込み量の平均(粒度300なので5分)が1024000(1メガバイト)を超えるとWARNING、2048000(2メガバイト)を超えるとCRITICALを検知するには以下のように設定します。
■ 監視設定例
正常に監視が出来ると以下の画像のようにステータス情報欄に「書き込みディスク量: ○ Byte」(○は数字)が表示されます。ディスクの書き込み量が多いと、大きいファイルの書き込みが行われている、アクセスが多く負荷が高くなっているなどの可能性があります。

23.2.5. EC2 DISK読込回数監視
監視グループ |
チェックコマンド |
|---|---|
AWS EC2 |
AWS/EC2 DISK読込回数監視 |
EC2インスタンスのディスクの読み込み回数を監視します。CloudWatchで確認できるMetric/DiskReadOpsの値で、指定した粒度での平均値が取得されます。
・監視設定例
読み込み回数の平均(粒度300なので5分)が100を超えるとWARNING、200を超えるとCRITICALを検知するには以下のように設定します。
■ 監視設定例
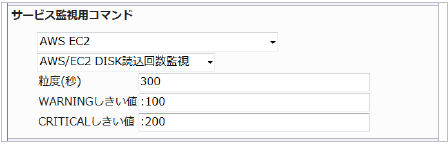
正常に監視が出来ると以下の画像のようにステータス情報欄に「読み込みディスク回数: ○ Count」(○は数字)が表示されます。ディスクの読み込み回数が多いと、アクセスするのに時間がかかっている可能性があります。

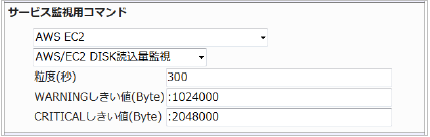
23.2.6. EC2 DISK読込量監視
監視グループ |
チェックコマンド |
|---|---|
AWS EC2 |
AWS/EC2 DISK読込量監視 |
EC2インスタンスのディスクの読み込み量を監視します。
CloudWatchで確認できるMetric/DiskReadBytesの値で、指定した粒度での平均値が取得されます。
・監視設定例
単位がByteのため、数字が大きくなりますのでご注意ください。
読込量の平均(粒度300なので5分)が1024000(1メガバイト)を超えるとWARNING、2048000(2メガバイト)を超えるとCRITICALを検知するには以下のように設定します。
■ 監視設定例
正常に監視が出来ると以下の画像のようにステータス情報欄に「読み込みディスク量: ○ Byte」(○は数字)が表示されます。
ディスクの読み込み量が多い場合、アクセスが多く負荷が高くなっているなどの可能性があります。

23.2.7. EC2 受信トラフィック監視
監視グループ |
チェックコマンド |
|---|---|
AWS EC2 |
AWS/EC2 受信トラフィック監視 |
EC2インスタンスのトラフィック受信量を監視します。
CloudWatchで確認できるMetric/NetworkInの値で、指定した粒度での平均値が取得されます。
・監視設定例
単位はbits, kbits, Mbits, Gbitsから選択できます。1k=10³=1000として計算されます。
受信トラフィック量の平均(粒度300なので5分)が800Mbitsを超えるとWARNING、 900Mbitsを超えるとCRITICALを検知するには以下のように設定します。
■ 監視設定例

正常に監視が出来ると以下の画像のようにステータス情報欄に「受信トラフィック: ○ [単位]bits/min」(○は数字)が表示されます。受信量が多いと、大きいファイルの転送がされている、アクセスが多いなどの可能性があります。
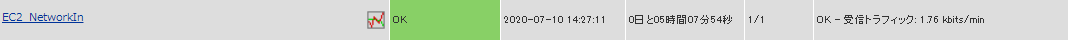
23.2.8. EC2 消費CPUクレジット数監視
※X-MON3.2で追加されたサービス監視コマンドになります。
監視グループ |
チェックコマンド |
|---|---|
AWS EC2 |
AWS/EC2 消費CPUクレジット数監視 |
EC2インスタンスの消費されたCPUクレジットを監視します。
CloudWatchで確認できるMetric/CPUCreditUsageの値で、指定した粒度での平均値が取得されます。
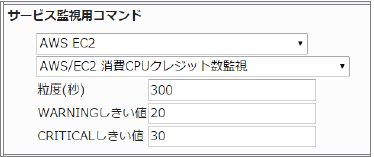
・監視設定例
消費されたCPUクレジット数の平均(粒度300なので5分)が20を超えるとWARNING、30を超えるとCRITICALを検知するには以下のように設定します。
■ 監視設定例
正常に監視が出来ると以下の画像のようにステータス情報欄に「消費CPUクレジット数: ○ count」(○は数字)が表示されます。

23.2.9. EC2 累積CPUクレジット数監視
※X-MON3.2で追加されたサービス監視コマンドになります。
監視グループ |
チェックコマンド |
|---|---|
AWS EC2 |
AWS/EC2 累積CPUクレジット数監視 |
蓄積されたCPUクレジットを監視します。CloudWatchで確認できるMetric/CPUCreditBalanceの値で、指定した粒度での平均値が取得されます。
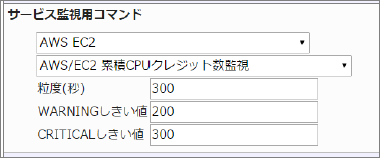
・監視設定例
累計CPUクレジット数の平均(粒度300なので5分)が200を超えるとWARNING、300を超えるとCRITICALを検知するには以下のように設定します。
■ 監視設定例
正常に監視が出来ると以下の画像のようにステータス情報欄に「累計CPUクレジット数: ○ count」(○は数字)が表示されます。

23.2.10. EC2 インスタンスステータスチェック結果監視
※X-MON3.2で追加されたサービス監視コマンドになります。
監視グループ |
チェックコマンド |
|---|---|
AWS EC2 |
AWS/EC2 インスタンスステータスチェック結果監視 |
インスタンスのステータスチェックに成功していればOKを返します。
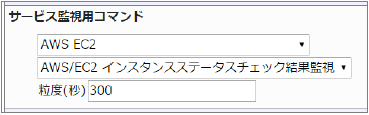
CloudWatchで確認できるMetric/StatusCheckFailed_Instanceの値で、指定した粒度での最大値(0または1)を取得し、0の場合は成功、1の場合は失敗とします。
■ 監視設定例
正常に監視が出来ると以下の画像のようにステータス情報欄に「インスタンスステータスチェック結果:成功」が表示されます。

23.2.11. EC2 システムステータスチェック結果監視
※X-MON3.2で追加されたサービス監視コマンドになります。
監視グループ |
チェックコマンド |
|---|---|
AWS EC2 |
AWS/EC2 システムステータスチェック結果監視 |
システムのステータスチェックに成功していればOKを返します。CloudWatchで確認できるMetric/StatusCheckFailed_Systemの値で、指定した粒度での最大値(0または1)を取得し、0の場合は成功、1の場合は失敗とします。
■ 監視設定例
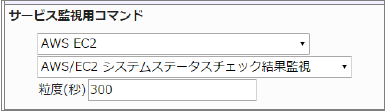
正常に監視が出来ると以下の画像のようにステータス情報欄に「システムステータスチェック結果: 成功」が表示されます。

23.2.12. EC2 ステータスチェック結果監視
※X-MON3.2で追加されたサービス監視コマンドになります。
監視グループ |
チェックコマンド |
|---|---|
AWS EC2 |
AWS/EC2 ステータスチェック結果監視 |
インスタンスおよびシステムのステータスチェックに成功していればOKを返します。CloudWatchで確認できるMetric/StatusCheckFailedの値で、指定した粒度での最大値(0または1)を取得し、0の場合は成功、1の場合は失敗とします。
■ 監視設定例
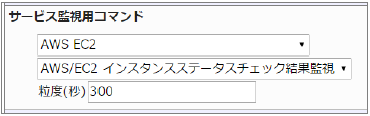
正常に監視が出来ると以下の画像のようにステータス情報欄に「ステータスチェック結果: 成功」が表示されます。

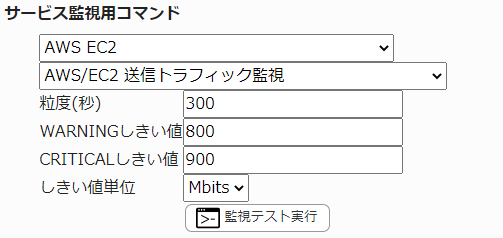
23.2.13. EC2 送信トラフィック監視
監視グループ |
チェックコマンド |
|---|---|
AWS EC2 |
AWS/EC2 送信トラフィック監視 |
EC2インスタンスのトラフィック送信量を監視します。CloudWatchで確認できるMetric/NetworkOutの値で、指定した粒度での平均値が取得されます。
・監視設定例
単位はbits, kbits, Mbits, Gbitsから選択できます。1k=10³=1000として計算されます。
送信トラフィック量の平均(粒度300なので5分)が800Mbitsを超えるとWARNING、 900Mbitsを超えるとCRITICALを検知するには以下のように設定します。
■ 監視設定例
正常に監視が出来ると以下の画像のようにステータス情報欄に「送信トラフィック: ○ [単位]bits/min」(○は数字)が表示されます。送信量が多いと、大きいファイルのダウンロードがされている、アクセスが多いなどの可能性があります。
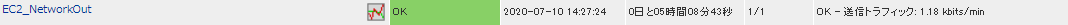
23.3. AWS ELB (アプリケーションロードバランサ) 監視
本章では AWS で使用できる Application Load Balancer の監視方法について解説します。
23.3.1. インスタンスID の指定について
ALB 監視のホスト設定においては、「AWS設定」タブの 「インスタンスID」 の値として、 ARN を元とした値を入力する必要があります。
この入力方法についてご説明します。その他の項目については AWS監視に必要な情報について をご参照ください。
23.3.1.1. ARN の確認
EC2 の「ロードバランサ一覧」画面に遷移し、監視したいロードバランサ(アプリケーションロードバランサ)の名称を選択します。
ロードバランサの詳細画面が開きますので、ARN を確認してください。
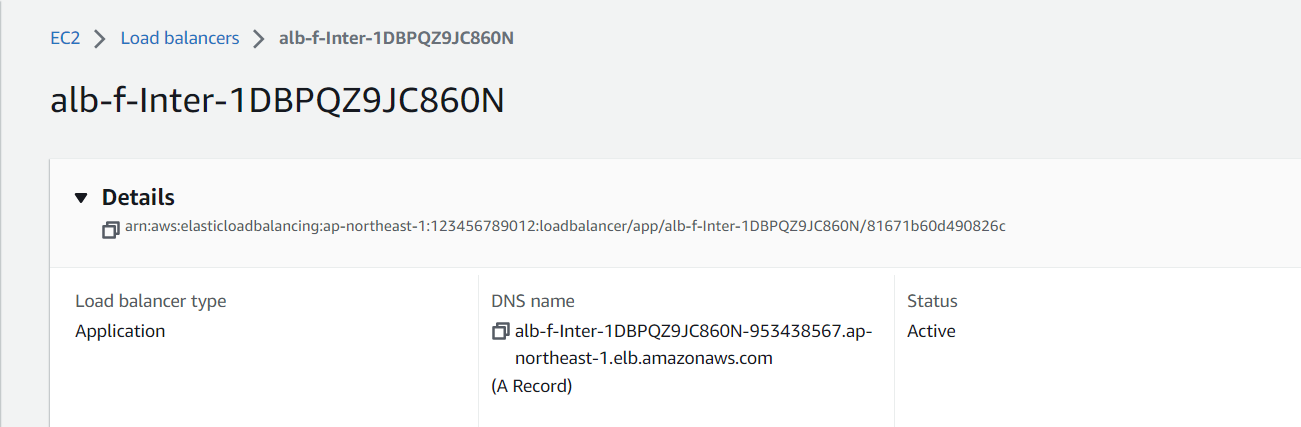
今回であれば、
arn:aws:elasticloadbalancing:ap-northeast-1:123456789012:loadbalancer/app/alb-f-Inter-1DBPQZ9JC860N/81671b60d490826c
となります。
23.3.1.2. 文字列の抜き出し
X-MON では、app/<load-balancer-name/<load-balancer-id> の形式でロードバランサを識別します。
今回であれば、
app/alb-f-Inter-1DBPQZ9JC860N/81671b60d490826c
となります。上記の形式で文字列を抜き出し、 「AWS設定」タブの「インスタンスID」欄に入力します。
23.3.2. 共通警告パターン
ELB (アプリケーションロードバランサ) 監視では CRITICAL、WARNING、UNKNOWN が警告パターンとなっております。
ステータス |
内容 |
|---|---|
CRITICAL |
CRITICAL のしきい値判定の結果 |
WARNING |
WARNING のしきい値判定の結果 |
UNKNOWN |
API のリクエストが送信できなかった場合
データの取得に失敗した場合
API のデータ通信は成功しているが、適切な値が取得できなかった場合
|
また、監視設定前に
をご確認ください。
23.3.3. 対応メトリクス一覧
統計値については、それぞれのメトリクスの内容に照らしてふさわしいものを選定しております。
メトリクスの一覧については AWS の公式ページ をご参照ください。
値が取得できない場合は、 0 を返します。
サービス監視コマンド |
対象メトリクス名称 |
算出される値 (統計値) |
|---|---|---|
同時接続数監視 |
ActiveConnectionCount |
合計値 (Sum) |
クライアントTLSネゴシエーションエラー数監視 |
ClientTLSNegotiationErrorCount |
合計値 (Sum) |
消費LCU数監視 |
ConsumedLCUs |
合計値 (Sum) |
RFC 7230 非準拠リクエスト数監視 |
DesyncMitigationMode_NonCompliant_Request_Count |
合計値 (Sum) |
不正ヘッダーを持つリクエストの削除数監視 |
DroppedInvalidHeaderRequestCount |
合計値 (Sum) |
認証エラー数監視 |
ELBAuthError |
合計値 (Sum) |
認証失敗数監視 |
ELBAuthFailure |
合計値 (Sum) |
認証遅延時間監視 |
ELBAuthLatency |
平均値 (Average) |
リフレッシュ数監視 |
ELBAuthRefreshTokenSuccess |
合計値 (Sum) |
認証成功数監視 |
ELBAuthSuccess |
合計値 (Sum) |
ユーザクレームサイズの重量超過数監視 |
ELBAuthUserClaimsSizeExceeded |
合計値 (Sum) |
不正ヘッダーを持つリクエストの転送数監視 |
ForwardedInvalidHeaderRequestCount |
合計値 (Sum) |
GRPCリクエスト数監視 |
GrpcRequestCount |
合計値 (Sum) |
有効インスタンス数監視 |
HealthyHostCount |
平均値 (Average) |
HTTPコード監視(ロードバランサ・3xx) |
HTTPCode_ELB_3XX_Count |
合計値 (Sum) |
HTTPコード監視(ロードバランサ・4xx) |
HTTPCode_ELB_4XX_Count |
合計値 (Sum) |
HTTPコード監視(ロードバランサ・500) |
HTTPCode_ELB_500_Count |
合計値 (Sum) |
HTTPコード監視(ロードバランサ・502) |
HTTPCode_ELB_502_Count |
合計値 (Sum) |
HTTPコード監視(ロードバランサ・503) |
HTTPCode_ELB_503_Count |
合計値 (Sum) |
HTTPコード監視(ロードバランサ・504) |
HTTPCode_ELB_504_Count |
合計値 (Sum) |
HTTPコード監視(ロードバランサ・5xx) |
HTTPCode_ELB_5XX_Count |
合計値 (Sum) |
HTTPコード監視(バックエンド・2xx) |
HTTPCode_Target_2XX_Count |
合計値 (Sum) |
HTTPコード監視(バックエンド・3xx) |
HTTPCode_Target_3XX_Count |
合計値 (Sum) |
HTTPコード監視(バックエンド・4xx) |
HTTPCode_Target_4XX_Count |
合計値 (Sum) |
HTTPコード監視(バックエンド・5xx) |
HTTPCode_Target_5XX_Count |
合計値 (Sum) |
固定レスポンス数監視 |
HTTP_Fixed_Response_Count |
合計値 (Sum) |
リダイレクト数監視 |
HTTP_Redirect_Count |
合計値 (Sum) |
リダイレクトURL文字数上限超過数監視 |
HTTP_Redirect_Url_Limit_Exceeded_Count |
合計値 (Sum) |
IPv6トラフィック処理バイト数監視 |
IPv6ProcessedBytes |
合計値 (Sum) |
IPv6リクエスト数監視 |
IPv6RequestCount |
合計値 (Sum) |
Lambda ターゲット内部エラー数監視 |
LambdaInternalError |
合計値 (Sum) |
Lambda ターゲット処理バイト数監視 |
LambdaTargetProcessedBytes |
合計値 (Sum) |
Lambda ターゲットユーザエラー数監視 |
LambdaUserError |
合計値 (Sum) |
新規接続数監視 |
NewConnectionCount |
合計値 (Sum) |
Sticky ではないリクエスト数監視 |
NonStickyRequestCount |
合計値 (Sum) |
処理データバイト数監視 |
ProcessedBytes |
合計値 (Sum) |
拒否接続数 |
RejectedConnectionCount |
合計値 (Sum) |
リクエスト数監視 |
RequestCount |
合計値 (Sum) |
ターゲットグループ別リクエスト数監視 |
RequestCountPerTarget |
平均値 (Sum)
利用している統計は Sum ですが、実際には平均値が取得されます。詳しくは AWS の公式ページ をご参照ください。
|
リスナールール評価数監視 |
RuleEvaluations |
合計値 (Sum) |
インスタンス接続エラー数監視 |
TargetConnectionErrorCount |
合計値 (Sum) |
反応速度監視 |
TargetResponseTime |
平均値 (Average) |
ターゲットグループ別TLSネゴシエーションエラー数監視 |
TargetTLSNegotiationErrorCount |
合計値 (Sum) |
無効インスタンス数監視 |
UnHealthyHostCount |
平均値 (Average) |
23.3.3.1. ターゲットグループを指定できるメトリクス
以下の監視についてはターゲットグループを指定できます。ターゲットグループの指定方法については後述します。
有効インスタンス数監視
HTTPコード監視(バックエンド・2xx)
HTTPコード監視(バックエンド・3xx)
HTTPコード監視(バックエンド・4xx)
HTTPコード監視(バックエンド・5xx)
ターゲットグループ別リクエスト数監視
インスタンス接続エラー数監視
反応速度監視
ターゲットグループ別TLSネゴシエーションエラー数監視
無効インスタンス数監視
ターゲットグループを指定した場合は、指定したターゲットグループに紐づくメトリクスの値を取得します。
ターゲットグループは、カンマ区切りで複数指定できます。
複数のターゲットグループを指定した場合、下記のメトリクスについては、得られた値の合計値を出力します。
有効インスタンス数監視
HTTPコード監視(バックエンド・2xx)
HTTPコード監視(バックエンド・3xx)
HTTPコード監視(バックエンド・4xx)
HTTPコード監視(バックエンド・5xx)
インスタンス接続エラー数監視
ターゲットグループ別TLSネゴシエーションエラー数監視
無効インスタンス数監視
複数のターゲットグループを指定した場合、下記のメトリクスについては、得られた値の平均値を出力します。
反応速度監視
ターゲットグループ別リクエスト数監視
なお、ターゲットグループを指定しなかった場合はターゲットグループなしでのリクエストを行います。
ターゲットグループを指定しなかった場合にどのような値が返ってくるかは、対象とするメトリクスによって異なります (ALB に紐づくすべてのターゲットグループの合計値、平均値を返す場合もあれば、何も返さない場合もあります)。
それぞれのメトリクスについて、ターゲットグループを指定しなかった場合にどのような値が取得できるかにつきましては、AWSの CloudWatch を確認すると共に、サービス設定時の監視テスト実行機能をご活用ください。
23.3.3.2. 値が取得できない場合、UNKNOWN のステータスとなるメトリクスについて
下記のメトリクスについては、対象の ALB, ターゲットグループが存在すれば必ず値が出力されます。
そのため、値が存在しない場合は異常と判定され、 UNKNOWN のステータスが返ります。
有効インスタンス数監視
無効インスタンス数監視
23.3.4. ターゲットグループの指定方法
ターゲットグループの指定においては、インスタンスID の指定の際と同様に ARN を元とした値を入力します。
23.3.4.1. ターゲットグループの ARN の確認方法
EC2 のターゲットグループ一覧画面より、ターゲットグループの詳細画面を開いて ARN を確認してください。
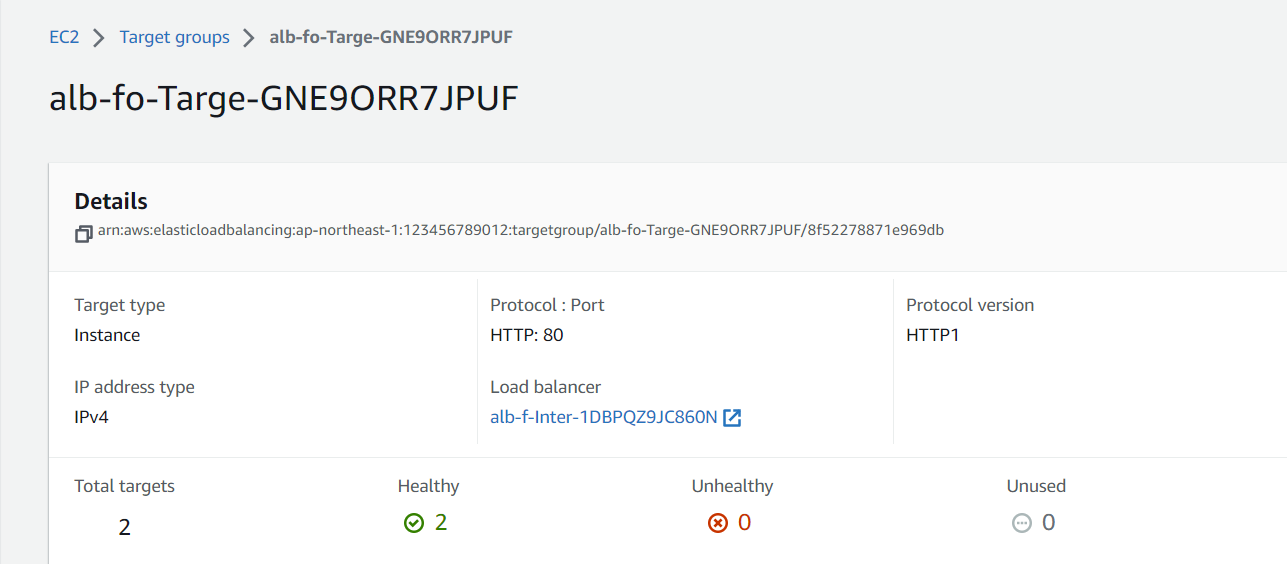
今回であれば、
arn:aws:elasticloadbalancing:ap-northeast-1:123456789012:targetgroup/alb-fo-Targe-GNE9ORR7JPUF/8f52278871e969db
となります。
23.3.4.2. 文字列の抜き出し
ARN から targetgroup/<target-group-name>/<target-group-id> の形式で文字列を抜き出し、入力してください。
今回であれば、
targetgroup/alb-fo-Targe-GNE9ORR7JPUF/8f52278871e969db
となります。この値を、 サービス設定の 「ターゲットグループ (カンマ区切り)」欄に入力します。
23.3.4.3. カンマ区切りでの複数指定
複数のターゲットグループを指定する場合は、カンマ区切りで入力します。
例えば、 targetgroup/alb-fo-Targe-GNE9ORR7JPUF/8f52278871e969db、targetgroup/alb-f-Targe-1AL5ZR1NZQERW/b0a76d4c66c4e7dc の二つの値を指定する場合は、
targetgroup/alb-fo-Targe-GNE9ORR7JPUF/8f52278871e969db, targetgroup/alb-f-Targe-1AL5ZR1NZQERW/b0a76d4c66c4e7dc
という形で入力します。なお、ターゲットグループを一つだけ入力する際のカンマは不要です。
23.4. AWS ELB (クラシックロードバランサ) 監視
本章ではAWSで使用できる Classic Load Balancer (CLB) の監視方法について解説します。
ホストの登録方法は ホストの登録方法 をご参照ください。
HTTP監視等のサービス監視を行う際はホストをFQDNで登録してください。
本章ではホスト名を「X-MON-Ref-ELB01」で登録し、粒度はデフォルトの300を使用します。
ELBの監視項目としてはHTTPコードの監視やリクエスト数、有効・無効インスタンス数が監視出来ますので、インスタンスの増減やリソースの調整にも役立つ項目となっております。
また、インスタンス配下からの応答HTTPコード、インスタンス自体の応答HTTPコードとわけて監視をする事が可能です。
23.4.1. 共通警告パターン
ELB監視ではCRITICAL、WARNING、UNKNOWNが警告パターンとなっております。
ステータス |
内容 |
|---|---|
CRITICAL |
・APIのリクエストが送信できなかった場合
・データの取得に失敗した場合
・CRITICALのしきい値判定の結果
|
WARNING |
・WARNINIGのしきい値判定の結果 |
UNKNOWN |
・APIのデータ通信は成功しているが、適切な値が取得できなかった場合 |
また、監視設定前に
を先にご確認ください。
23.4.2. ELB HTTPコード監視(バックエンド・2xx)
監視グループ |
チェックコマンド |
|---|---|
AWS ELB (クラシックロードバランサ) |
AWS/CLB HTTPコード監視 (バックエンド・2xx) |
ELBインスタンス配下のインスタンスが返したHTTPコードの内、200番台のコードの数を監視します。
CloudWatchで確認できるMetric/HTTPCode_Backend_2XXの値で、指定した粒度での合計値が取得されます。
CloudWatchにて値が記録されていない場合、該当のコードが出力されなかったものとして扱い、0を返します。
・監視設定例
HTTPコードの200番台は一般的にアクセスが成功した時の応答コードとなります。
そのため監視の閾値としては配下のインスタンス数より小さい値が閾値の選定ポイントとなります。
応答数の合計(粒度300なので5分)が2でWARNING、1でCRITICALを検知するようにするには以下のように設定します。
■ 監視設定例
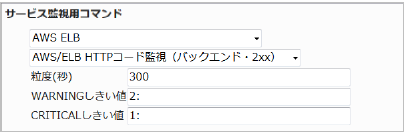
正常に監視できると以下の画像のようにステータス情報欄に「HTTP 2xxコード: ○ Count」(○は数字)が表示されます。 応答コード数が少なくなるとHTTP応答がしていないのでインスタンスに問題が発生している可能性があります。

23.4.3. ELB HTTPコード監視(バックエンド・3xx)
監視グループ |
チェックコマンド |
|---|---|
AWS ELB (クラシックロードバランサ) |
AWS/CLB HTTPコード監視 (バックエンド・3xx) |
ELBインスタンス配下のインスタンスが返したHTTPコードの内、300番台のコードの数を監視します。
CloudWatchで確認できるMetric/HTTPCode_Backend_3XXの値で、指定した粒度での合計値が取得されます。CloudWatchにて値が記録されていない場合、該当のコードが出力されなかったものとして扱い、0を返します。
・監視設定例
HTTPコードの300番台は一般的にリダイレクションの応答コードとなります。
そのため監視の閾値としては配下のインスタンスにてリダイレクションが設定されているか確認する事が閾値の選定ポイントとなります。
応答数の合計(粒度300なので5分)が3でWARNING、1でCRITICALを検知するようにするには以下のように設定します。
■ 監視設定例

正常に監視できると以下の画像のようにステータス情報欄に「HTTP 3xxコード: ○ Count」(○は数字)が表示されます。リダイレクションを設定している場合、コード数が少なくなるとインスタンスに問題が発生している可能性があります。

23.4.4. ELB HTTPコード監視(バックエンド・4xx)
監視グループ |
チェックコマンド |
|---|---|
AWS ELB (クラシックロードバランサ) |
AWS/CLB HTTPコード監視 (バックエンド・4xx) |
ELBインスタンス配下のインスタンスが返したHTTPコードの内、400番台のコードの数を監視します。
CloudWatchで確認できるMetric/HTTPCode_Backend_4XXの値で、指定した粒度での合計値が取得されます。
CloudWatchにて値が記録されていない場合、該当のコードが出力されなかったものとして扱い、0を返します。
・監視設定例
HTTPコードの400番台は一般的にクライアントエラーの応答コードとなります。
400番台が増えるとアクセスが成功していないのでリンクのアドレスの間違いなども考えられます。
またBasic認証をしていて認証失敗している場合も400番台(401)が返されます。そのため大きい値を検知すれば障害とするようにします。
応答数の合計(粒度300なので5分)が10でWARNING、15でCRITICALを検知するようにするには以下のように設定します。
■ 監視設定例
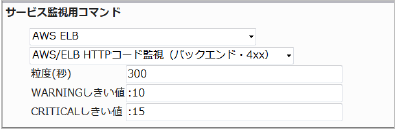
正常に監視できると以下の画像のようにステータス情報欄に「HTTP 4xxコード: ○ Count」(○は数字)が表示されます。コードが多くなるとHTTPにてエラーが発生している可能性があります。

23.4.5. ELB HTTPコード監視(バックエンド・5xx)
監視グループ |
チェックコマンド |
|---|---|
AWS ELB (クラシックロードバランサ) |
AWS/CLB HTTPコード監視 (バックエンド・5xx) |
ELBインスタンス配下のインスタンスが返したHTTPコードの内、500番台のコードの数を監視します。
CloudWatchで確認できるMetric/HTTPCode_Backend_5XXの値で、指定した粒度での合計値が取得されます。
CloudWatchにて値が記録されていない場合、該当のコードが出力されなかったものとして扱い、0を返します。
・監視設定例
HTTPコードの500番台は一般的サーバーエラーの応答コードとなります。
500番台が増えるサービスが稼働していない、または稼働しているがエラーとなっている可能性があります。そのため大きい値を検知すれば障害とするようにします。
応答数の合計(粒度300なので5分)が10でWARNING、15でCRITICALを検知するようにするには以下のように設定します。
■ 監視設定例

正常に監視できると以下の画像のようにステータス情報欄に「HTTP 5xxコード: ○ Count」(○は数字)が表示されます。コード数が多くなるとインスタンスに問題が発生している可能性があります。

23.4.6. ELB HTTPコード監視(ロードバランサ・4xx)
監視グループ |
チェックコマンド |
|---|---|
AWS ELB (クラシックロードバランサ) |
AWS/CLB HTTPコード監視 (ロードバランサ・4xx) |
ELBインスタンスが返したHTTPコードの内、400番台のコードの数を監視します。
CloudWatchで確認できるMetric/HTTPCode_ELB_4XXの値で、指定した粒度での合計値が取得されます。
CloudWatchにて値が記録されていない場合、該当のコードが出力されなかったものとして扱い、0を返します。
・監視設定例
Classic Load Balancer自体からのHTTPコード数を監視します。
400番台が増えるとアクセスが成功していないのでリンクのアドレスの間違いなども考えられます。
またBasic認証をしていて認証失敗している場合も400番台(401)が返されます。そのため大きい値を検知すれば障害とするようにします。
配下のインスタンス数が多いほど、値は大きくても許容範囲が大きくはなりますがお客様の許容範囲で選定する事となります。
応答数の合計(粒度300なので5分)が15でWARNING、20でCRITICALを検知するようにするには以下のように設定します。
■ 監視設定例

正常に監視できると以下の画像のようにステータス情報欄に「HTTP 4xxコード: ○ Count」(○は数字)が表示されます。コード数が多いとアクセスが多くなっている可能性や配下インスタンスで問題が発生している可能性があります。

23.4.7. ELB HTTPコード監視(ロードバランサ・5xx)
監視グループ |
チェックコマンド |
|---|---|
AWS ELB (クラシックロードバランサ) |
AWS/CLB HTTPコード監視 (ロードバランサ・5xx) |
ELBインスタンスが返したHTTPコードの内、500番台のコードの数を監視します。
CloudWatchで確認できるMetric/HTTPCode_ELB_5XXの値で、指定した粒度での合計値が取得されます。
CloudWatchにて値が記録されていない場合、該当のコードが出力されなかったものとして扱い、0を返します。
・監視設定例
Classic Load Balancer自体からのHTTPコード数を監視します。
500番台が増えるサービスが稼働していない、または稼働しているがエラーとなっている可能性があります。そのため大きい値を検知すれば障害とするようにします。
配下のインスタンス数が多いほど、値は大きくても許容範囲が大きくはなりますがお客様の許容範囲で選定する事となります。
応答数の合計(粒度300なので5分)が15でWARNING、20でCRITICALを検知するようにするには以下のように設定します。
■ 監視設定例
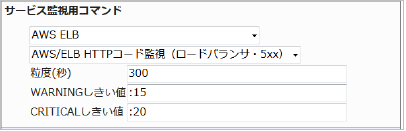
正常に監視できると以下の画像のようにステータス情報欄に「HTTP 4xxコード: ○ Count」(○は数字)が表示されます。応答数が多いとアクセスが多くなっている可能性や配下インスタンスで問題が発生している可能性があります。

23.4.8. ELB リクエスト数監視
監視グループ |
チェックコマンド |
|---|---|
AWS ELB (クラシックロードバランサ) |
AWS/CLB リクエスト数監視 |
ELBインスタンスに対するHTTPリクエストの数を監視します。
CloudWatchで確認できるMetric/RequestCountの値で、指定した粒度での合計値が取得されます。CloudWatchにて値が記録されていない場合、リクエストが発生しなかったものとして扱い、0を返します。
・監視設定例
この監視の数値が増えるということはアクセスが増加しているということを示しますので、この監視を起点に、インスタンスの増減やインスタンスの設定の調整などの対応を検討・実施することができます。
リクエスト数の合計(粒度300なので5分)が150でWARNING、200でCRITICALを検知するようにするには以下のように設定します。
■ 監視設定例
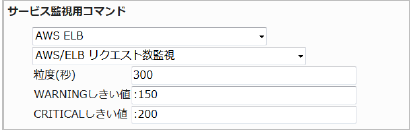
正常に監視できると以下の画像のようにステータス情報欄に「リクエスト数: ○ request」(○は数字)が表示されます。アクセスの多さを確認する指標にもなります。

23.4.9. ELB 反応速度監視
監視グループ |
チェックコマンド |
|---|---|
AWS ELB (クラシックロードバランサ) |
AWS/CLB 反応速度監視 |
ELBインスタンスの反応速度を監視します。
CloudWatchで確認できるMetric/Latencyの値で、指定した粒度での平均値が取得されます。CloudWatchにて値が記録されていない場合、接続がなく遅延も発生しなかったものとして扱い、0を返します。
・監視設定例
アクセス数の増加によるリソースのひっ迫等で、応答速度が遅くなる事があります。
そのため閾値の選定ポイントとしては上限を設定し、応答速度が遅くなると障害として検知するようにします。
応答速度の平均(粒度300なので5分)が3秒でWARNING、5秒でCRITICALを検知するようにするには以下のように設定します。
■ 監視設定例
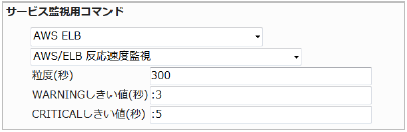
正常に監視できると以下の画像のようにステータス情報欄に「レイテンシ: ○ sec」(○は数字)が表示されます。応答速度を確認する指標にもなります。

23.4.10. ELB 拒否リクエスト数監視
※X-MON3.2で追加されたサービス監視コマンドになります。
監視グループ |
チェックコマンド |
|---|---|
AWS ELB (クラシックロードバランサ) |
AWS/CLB 拒否リクエスト数監視 |
拒否されたリクエスト数を監視します。
CloudWatchで確認できるMetric/SpilloverCountの値で、指定した粒度での合計値が取得されます。
・監視設定例
応答速度の平均(粒度300なので5分)が50でWARNING、100でCRITICALを検知するようにするには以下のように設定します。
■ 監視設定例
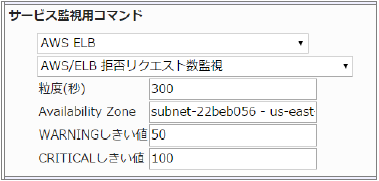
正常に監視できると以下の画像のようにステータス情報欄に「拒否リスエスト数: ○ count」(○は数字)が表示されます。

23.4.11. ELB インスタンス接続エラー数監視
※X-MON3.2で追加されたサービス監視コマンドになります。
監視グループ |
チェックコマンド |
|---|---|
AWS ELB (クラシックロードバランサ) |
AWS/CLB インスタンス接続エラー数監視 |
Classic Load Balancerとインスタンス間で正常に確立されなかった接続数を監視します。
CloudWatchで確認できるMetric/BackendConnectionErrorsの値で、指定した粒度での合計値が取得されます。
・監視設定例
応答速度の平均(粒度300なので5分)が50でWARNING、100でCRITICALを検知するようにするには以下のように設定します。
■ 監視設定例
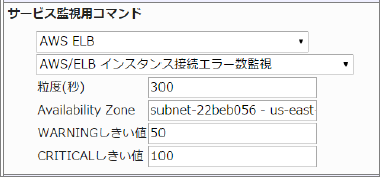
正常に監視できると以下の画像のようにステータス情報欄に「インスタンス接続エラー数: ○ count」(○は数字)が表示されます。

23.4.12. ELB 保留リクエスト数監視
※X-MON3.2で追加されたサービス監視コマンドになります。
監視グループ |
チェックコマンド |
|---|---|
AWS ELB (クラシックロードバランサ) |
AWS/CLB 保留リクエスト数監視 |
保留中のリクエスト数を監視します。
CloudWatchで確認できるMetric/SurgeQueueLengthの値で、指定した粒度での最大値が取得されます。
・監視設定例
保留中のリクエスト数の平均(粒度300なので5分)が50以上でWARNING、100以上でCRITICALを検知するようにするには以下のように設定します。
■ 監視設定例
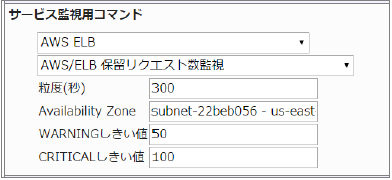
正常に監視できると以下の画像のようにステータス情報欄に「保留リクエスト数: ○ count」(○は数字)が表示されます。

23.4.13. ELB 有効インスタンス数監視
監視グループ |
チェックコマンド |
|---|---|
AWS ELB (クラシックロードバランサ) |
AWS/CLB 有効インスタンス数監視 |
ELBインスタンス配下の有効インスタンス数を監視します。
CloudWatchで確認できるMetric/HealthyHostCountの値で、指定した粒度での平均値が取得されます。
・監視設定例
ap-northeast-1aのAvailability Zoneに有効数の平均(粒度300なので5分)が3でWARNING、1でCRITICALを検知するようにするには以下のように設定します。
■ 監視設定例
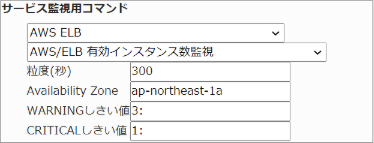
正常に監視できると以下の画像のようにステータス情報欄に「有効インスタンス数: ○ 」(○は数字)が表示されます。配下インスタンスに問題が発生していないか確認ができます。

ELBの設定でCross-zone load balancingが有効の場合、Availability Zoneを空白にしてください。 無効の場合は、各インスタンスが所属するAvailability Zoneを指定してください。複数存在する場合はカンマ区切りで指定が可能です。
23.4.14. ELB 無効インスタンス数監視
監視グループ |
チェックコマンド |
|---|---|
AWS ELB (クラシックロードバランサ) |
AWS/CLB 無効インスタンス数監視 |
ELBインスタンス配下の無効インスタンス数を監視します。
CloudWatchで確認できるMetric/UnHealthyHostCountの値で、指定した粒度での平均値が取得されます。
・監視設定例
有効インスタンス数監視とは反対で無効のインスタンスの数を監視します。
無効な数なので上限を設定するように閾値を設定します。
無効数の平均(粒度300なので5分)が2でWARNING、4でCRITICALを検知するようにするには以下のように設定します。
■ 監視設定例
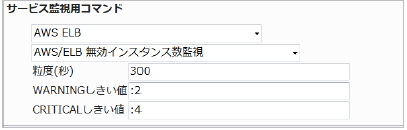
正常に監視できると以下の画像のようにステータス情報欄に「無効インスタンス数: ○ 」(○は数字)が表示されます。配下インスタンスに問題が発生していないか確認ができます。

23.5. AWS RDS監視
本章ではAWSで使用出来るデータベースサーバのRDSの監視方法について解説します。ホストの登録方法は ホストの登録方法 をご参照ください。[インスタンス名]項目には、「DB 識別子」をご入力ください。
本章ではホスト名を「X-MON-Ref-DB01」で登録し、粒度はデフォルトの300を使用します。
データベースサーバのため、CPU使用率やストレージの空き容量、ディスクへのアクセスリソースに加え、ログの文字列監視、SWAP使用量監視にも対応しております。
リソースが多く使われるインスタンスであり、負荷状況を確認するにもX-MONであればグラフ確認や値を確認し、事前に容量不足やリソース不足になる前に対応できる助けになります。
23.5.1. 共通警告パターン
RDS監視ではCRITICAL、WARNING、UNKNOWNが警告パターンとなっております。
ステータス |
内容 |
|---|---|
CRITICAL |
・APIのリクエストが送信できなかった場合
・データの取得に失敗した場合
・CRITICALのしきい値判定の結果
|
WARNING |
・WARNINGのしきい値判定の結果 |
UNKNOWN |
・APIのデータ通信は成功しているが、適切な値が取得できなかった場合 |
また、監視設定前に
を先にご確認ください。
23.5.2. RDS CPU使用率監視
監視グループ |
チェックコマンド |
|---|---|
AWS RDS |
AWS/RDS CPU使用率監視 |
RDSインスタンスのCPU使用率を監視します。
CloudWatchで確認できるMetric/CPUUtilizationの値で、指定した粒度での平均値が取得されます。
・監視設定例
CPU使用率が高いとインスタンスの負荷が高くなりサービスに影響が出る可能性があります。
CPU使用率の平均(粒度300なので5分)が30%を超えるとWARNING、50%を超えるとCRITICALを検知するようにするには以下のように設定します。
■ 監視設定例
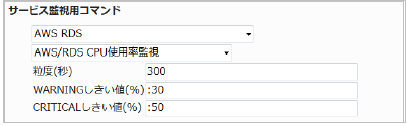
正常に監視が出来ると以下の画像のようにステータス情報欄に「CPU使用率: ○ %」(○は数字)が表示されます。

23.5.3. RDS DB接続数監視
監視グループ |
チェックコマンド |
|---|---|
AWS RDS |
AWS/RDS DB接続数監視 |
RDSインスタンスのデータベースへのコネクション数を監視します。
CloudWatchで確認できるMetric/DatabaseConnectionsの値で、指定した粒度での合計値が取得されます。
・監視設定例
DB接続数が多いと、DB処理待ちによる反応の遅延やプログラムが原因で正しく処理が行われていない可能性があり、パフォーマンスに影響が出てきます。
そのため閾値としては上限を設定するようにします。
DB接続数の合計(粒度300なので5分)が100を超えるとWARNING、150を超えるとCRITIALを検知するようにするには以下のように設定します。
■ 監視設定例
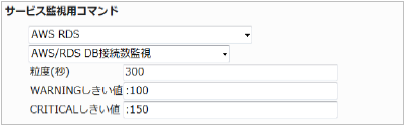
正常に監視が出来ると以下の画像のようにステータス情報欄に「DB接続数: ○ connection」(○は数字)が表示されます。

23.5.4. RDS DISK書込監視(IOPS)
監視グループ |
チェックコマンド |
|---|---|
AWS RDS |
AWS/RDS DISK書込監視(IOPS) |
RDSインスタンスの書き込みの平均IOPS (Input/Output Per Second)を監視します。
CloudWatchで確認できるMetric/WriteIOPSの値で、指定した粒度での平均値が取得されます。
・監視設定例
ディスクの書き込み回数が多いと、アクセスが多い時や負荷が高くなっている可能性があります。
書き込み回数の平均(粒度300なので5分)が100を超えるとWARNING、200を超えるとCRITICALを検知するには以下のように設定します。
■ 監視設定例
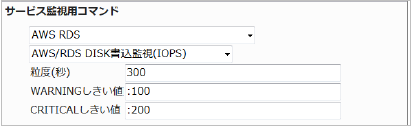
正常に監視が出来ると以下の画像のようにステータス情報欄に「書き込みの平均IOPS: ○ count/sec」(○は数字)が表示されます。

23.5.5. RDS DISK書込監視(スループット)
監視グループ |
チェックコマンド |
|---|---|
AWS RDS |
AWS/RDS DISK書込監視(スループット) |
RDSインスタンスの書き込みスループットを監視します。
CloudWatchで確認できるMetric/WriteThroughputの値で、指定した粒度での平均値が取得されます。
・監視設定例
単位がByteのため、数字が大きくなりますのでご注意ください。
スループットが高いとアクセスや処理が多くなっている事があります。
スループットの平均(粒度300なので5分)が1024000(1メガバイト)超えるとWARNING、2048000(2メガバイト)を超えるとCRITICALを検知するには以下のように設定します。
■ 監視設定例
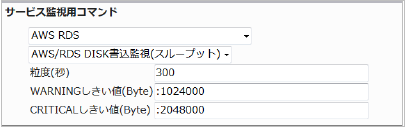
正常に監視が出来ると以下の画像のようにステータス情報欄に「書き込みの平均スループット: ○ Byte/Sec」(○は数字)が表示されます。

23.5.6. RDS DISK書込監視(レイテンシ)
監視グループ |
チェックコマンド |
|---|---|
AWS RDS |
AWS/RDS DISK書込監視(レイテンシ) |
RDSインスタンスの書き込みのレイテンシを監視します。
CloudWatchで確認できるMetric/WriteLatencyの値で、指定した粒度での平均値が取得されます。
・監視設定例
DISKへの書込の遅延が発生するとアクセスが多くなっている、リソース不足で負荷が高くなっている可能性があります。単位は秒で設定しますので上限で設定します。
レイテンシの平均(粒度300なので5分)が1を超えるとWARNING、2を超えるとCRITICALを検知するには以下のように設定します。
■ 監視設定例
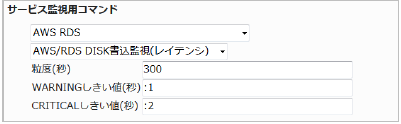
正常に監視が出来ると以下の画像のようにステータス情報欄に「書き込みの平均レイテンシ: ○ second」(○は数字)が表示されます。

23.5.7. RDS DISK読込監視(IOPS)
監視グループ |
チェックコマンド |
|---|---|
AWS RDS |
AWS/RDS DISK読込監視(IOPS) |
RDSインスタンスの読み込みの平均IOPS (Input/Output Per Second)を監視します。
CloudWatchで確認できるMetric/ReadIOPSの値で、指定した粒度での平均値が取得されます。
・監視設定例
ディスクの読み込み回数が多いと、アクセスが多く負荷が高くなっているなどの可能性があります。
書き込み回数の平均(粒度300なので5分)が100を超えるとWARNING、200を超えるとCRITICALを検知するには以下のように設定します。
■ 監視設定例
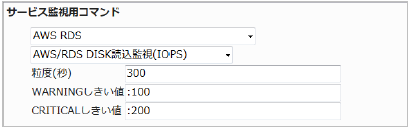
正常に監視が出来ると以下の画像のようにステータス情報欄に「読み込みの平均IOPS: ○ count/sec」(○は数字)が表示されます。

23.5.8. RDS DISK読込監視(スループット)
監視グループ |
チェックコマンド |
|---|---|
AWS RDS |
AWS/RDS DISK読込監視(スループット) |
RDSインスタンスの読み込みスループットを監視します。
CloudWatchで確認できるMetric/ReadThroughputの値で、指定した粒度での平均値が取得されます。
・監視設定例
単位がByteのため、数字が大きくなりますのでご注意ください。
スループットの平均が高い場合、アクセスや処理が多くなっている可能性があります。
スループットの平均(粒度300なので5分)が1024000(1メガバイト)を超えるとWARNING、2048000(2メガバイト)を超えるとCRITICALを検知するには以下のように設定します。
■ 監視設定例
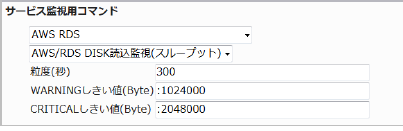
正常に監視が出来ると以下の画像のようにステータス情報欄に「読み込みの平均スループット: ○ Byte/Sec」(○は数字)が表示されます。

23.5.9. RDS DISK読込監視(レイテンシ)
監視グループ |
チェックコマンド |
|---|---|
AWS RDS |
AWS/RDS DISK読込監視(レイテンシ) |
RDSインスタンスの読み込みのレイテンシを監視します。
CloudWatchで確認できるMetric/ReadLatencyの値で、指定した粒度での平均値が取得されます。
・監視設定例
DISKへの読み込みの遅延が発生するとアクセスが多くなっている、リソース不足で負荷が高くなっているなどの可能性があります。単位は秒で指定します。
レイテンシの平均(粒度300なので5分)が1を超えるとWARNING、2を超えるとCRITICALを検知するには以下のように設定します。
■ 監視設定例
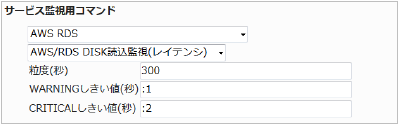
正常に監視が出来ると以下の画像のようにステータス情報欄に「読み込みの平均レイテンシ: ○ second」(○は数字)が表示されます。

23.5.10. RDS SWAP使用量監視
監視グループ |
チェックコマンド |
|---|---|
AWS RDS |
AWS/RDS SWAP使用量監視 |
RDSインスタンスのSWAP使用量を監視します。
CloudWatchで確認できるMetric/SwapUsageの値で、指定した粒度での平均値が取得されます。
・監視設定例
単位がByteのため、数字が大きくなりますのでご注意ください。
SWAP使用量が増えるとRDSで使用しているデータベースサービスの負荷が高くなっている、リソースが不足しているなどの可能性があります。
SWAP使用量の平均(粒度300なので5分)が512000000 (500メガバイト) を超えるとWARNING、1024000000 (1ギガバイト) を超えるとCRITICALを検知するには以下のように設定します。
■ 監視設定例
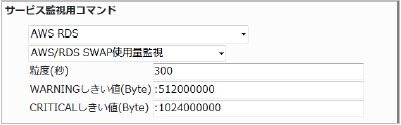
正常に監視が出来ると以下の画像のようにステータス情報欄に「SWAP使用量: ○ MB」(○は数字)が表示されます。

23.5.11. RDS 受信トラフィック監視
※X-MON3.2で追加されたサービス監視コマンドになります。
監視グループ |
チェックコマンド |
|---|---|
AWS RDS |
AWS/RDS 受信トラフィック監視 |
RDSインスタンスの受信トラフィックを監視します。
CloudWatchで確認できるMetric/NetworkReceiveThroughputの値で、指定した粒度での平均値が取得されます。
・監視設定例
単位はbytes, kbytes, Mbytes, Gbytesから選択できます。1k=10³=1000として計算されます。
受信トラフィック量の平均(粒度300なので5分)が500Mbytesを超えるとWARNING、1Gbytesを超えるとCRITICALを検知するには以下のように設定します。
■ 監視設定例
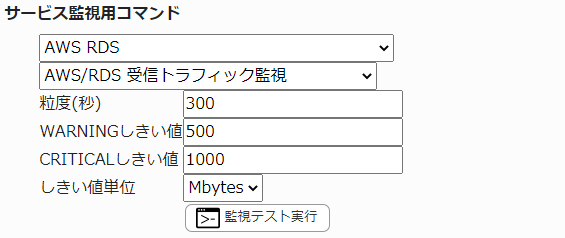
正常に監視が出来ると以下の画像のようにステータス情報欄に「受信トラフィック: ○ [単位]bytes/sec」(○は数字)が表示されます。
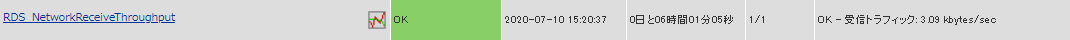
23.5.12. RDS 未処理のDISKリクエスト数監視
※X-MON3.2で追加されたサービス監視コマンドになります。
監視グループ |
チェックコマンド |
|---|---|
AWS RDS |
AWS/RDS 未処理のDISKリクエスト数監視 |
RDSインスタンスの未処理のディスクI/Oアクセス数を監視します。CloudWatchで確認できるMetric/DiskQueueDepthの値で、指定した粒度での平均値が取得されます。
・監視設定例
未処理のDISKリクエスト数の平均(粒度300なので5分)が500を超えるとWARNING、1000を超えるとCRITICALを検知するには以下のように設定します。
■ 監視設定例

正常に監視が出来ると以下の画像のようにステータス情報欄に「未処理のDISKリクエスト数: ○ count.」(○は数字)が表示されます。

23.5.13. RDS 消費CPUクレジット数監視
※X-MON3.2で追加されたサービス監視コマンドになります。
監視グループ |
チェックコマンド |
|---|---|
AWS RDS |
AWS/RDS 消費CPUクレジット数監視 |
RDSインスタンスの消費されたCPUクレジット数を監視します。CloudWatchで確認できるMetric/CPUCreditUsageの値で、指定した粒度での平均値が取得されます。
・監視設定例
消費されたCPUクレジット数の平均(粒度300なので5分)が30を超えるとWARNING、40を超えるとCRITICALを検知するには以下のように設定します。
■ 監視設定例

正常に監視が出来ると以下の画像のようにステータス情報欄に「消費CPUクレジット数: ○ count.」(○は数字)が表示されます。

23.5.14. RDS ログ監視
監視グループ |
チェックコマンド |
|---|---|
AWS RDS |
AWS/RDS ログ監視 |
RDSインスタンスのデータベースのログを監視します。
RDSのDBインスタンスのLogsに出力されるログ情報を取得し、指定したキーワードの文字列を検出すると警告を発生させます。もし、キーワードが指定されていない場合は、新たなログが増える毎に警告が発生します。
また、IAMユーザを使用する際は「Power User Access」の権限が必要となります。
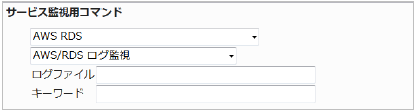
・入力項目
入力項目は以下となります。
■ 入力項目
項目 |
内容 |
|---|---|
ログファイル |
監視対象のログファイルを指定します。
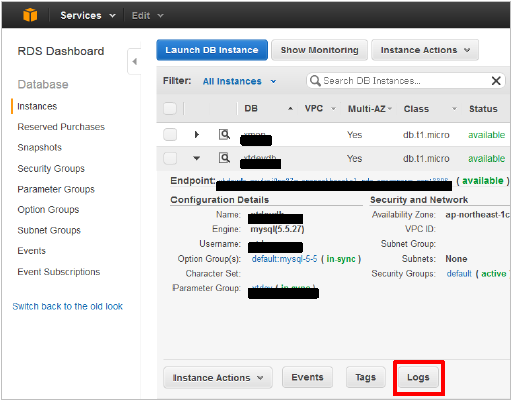
ログファイルは、AWSの管理コンソールからRDSを選択し、
DB Instanceを選択し、Logsのタブで確認できます。
|
キーワード |
検出したいキーワードを記述します。大文字小文字は判別され、
入力したキーワードは部分一致で検索されます。
また、カンマ区切りで複数のキーワードを指定出来ます。
キーワードが指定されていない場合は、新たなログが増える事に警告が発生します。
|
■ DBインスタンス
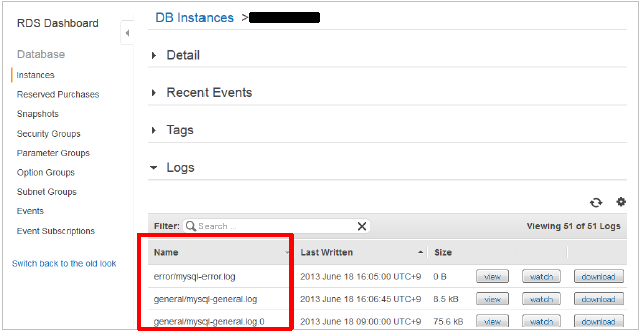
■ ログファイル名
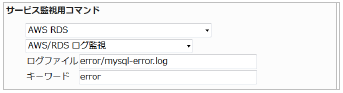
・監視設定例
ログファイル「error/mysql-error.log」にて「error」を検索する場合は以下のように設定します。
■ 監視設定例
正常に監視が出来ると以下の画像のようにステータス情報欄に「エラー文字列は存在しません」(○は数字)が表示されます。
■ ログ監視

該当のキーワードを検知すると以下のように「エラー文字列を検出しました」と表示されます。複数のキーワードを指定している場合、どのキーワードで検出したかは表示がされませんのでご注意ください。
■ ログ監視検知時

ログを確認される際は、ログ一覧の画面にて「view」ボタンをクリックするとログを表示する事が出来ますので、ご確認ください。
■ ログ一覧
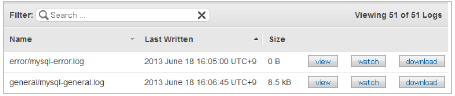
■ ログファイル表示時
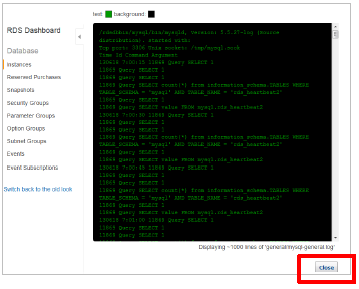
Closeボタンをクリックするとログ一覧の画面に戻ります。
23.5.15. RDS 空きストレージ監視
監視グループ |
チェックコマンド |
|---|---|
AWS RDS |
AWS/RDS 空きストレージ監視 |
RDSインスタンスのストレージの空き容量を監視します。
CloudWatchで確認できるMetric/FreeStorageSpaceの値で、指定した粒度での最小の値が取得されます。
・監視設定例
単位がByteのため、数字が大きくなりますのでご注意ください。
空きストレージが少なくなるとデータの保存が出来なくなりサービス稼働に影響が出る可能性があります。閾値は下限で設定します。
空き容量の平均(粒度300なので5分)が4000000000 (4ギガバイト) を下回るとWARNING、2000000000 (2ギガバイト) を下回るとCRITICALを検知するには以下のように設定します。
■ 監視設定例
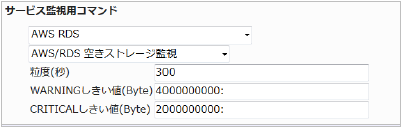
正常に監視が出来ると以下の画像のようにステータス情報欄に「空きストレージ容量: ○ MB」(○は数字)が表示されます。

23.5.16. RDS 空きメモリ監視
監視グループ |
チェックコマンド |
|---|---|
AWS RDS |
AWS/RDS 空きメモリ監視 |
RDSインスタンスのメモリの空き容量を監視します。
CloudWatchで確認できるMetric/FreeableMemoryの値で、指定した粒度での平均値が取得されます。
・監視設定例
閾値は下限で設定します。
空き容量の平均 (粒度300なので5分) が128000000 (128メガバイト) を下回るとWARNING、100000000 (100メガバイト) を下回るとCRITICALを検知するには以下のように設定します。
■ 監視設定例
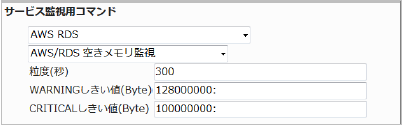
正常に監視が出来ると以下の画像のようにステータス情報欄に「空きメモリ: ○ MB」(○は数字)が表示されます。

23.5.17. RDS 累積CPUクレジット数監視
※X-MON3.2で追加されたサービス監視コマンドになります。
監視グループ |
チェックコマンド |
|---|---|
AWS RDS |
AWS/RDS 累積CPUクレジット数監視 |
RDSインスタンスの累積されたCPUクレジット数を監視します。CloudWatchで確認できるMetric/CPUCreditBalanceの値で、指定した粒度での平均値が取得されます。
・監視設定例
累積されたCPUクレジット数の平均(粒度300なので5分)が30を超えるとWARNING、40を超えるとCRITICALを検知するには以下のように設定します。
■ 監視設定例

正常に監視が出来ると以下の画像のようにステータス情報欄に「累積CPUクレジット数: ○ count.」(○は数字)が表示されます。

23.5.18. RDS 送信トラフィック監視
※X-MON3.2で追加されたサービス監視コマンドになります。
監視グループ |
チェックコマンド |
|---|---|
AWS RDS |
AWS/RDS 送信トラフィック監視 |
RDSインスタンスの送信トラフィックを監視します。
CloudWatchで確認できるMetric/NetworkTransmitThroughputの値で、指定した粒度での平均値が取得されます。
・監視設定例
単位はbytes, kbytes, Mbytes, Gbytesから選択できます。1k=10³=1000として計算されます。
送信トラフィックの平均(粒度300なので5分)が500Mbyteを超えるとWARNING、1Gbyteを超えるとCRITICALを検知するには以下のように設定します。
■ 監視設定例
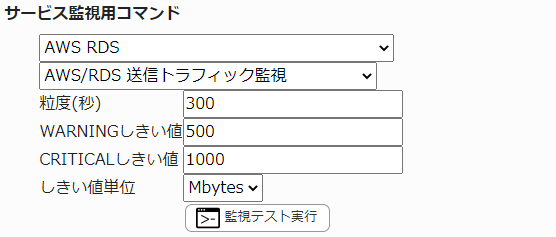
正常に監視が出来ると以下の画像のようにステータス情報欄に「送信トラフィック: ○[単位]bytes/sec」(○は数字)が表示されます。
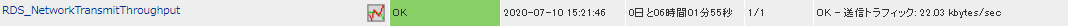
23.5.19. RDS レプリケーション遅延監視
※X-MON3.2で追加されたサービス監視コマンドになります。
監視グループ |
チェックコマンド |
|---|---|
AWS RDS |
AWS/RDS レプリケーション遅延監視 |
レプリケーション遅延時間を監視します。
本コマンドはリードレプリカRDSインスタンスのホストへ登録してください。
CloudWatchで確認できるMetric/ReplicaLagの値で、指定した粒度での平均値が取得されます。
以下、監視対応表です。
MySQL |
MariaDB |
PostgreSQL |
Amazon Aurora |
Oracle |
MSSQL |
|---|---|---|---|---|---|
○ |
○ |
○ |
× |
× |
× |
・監視設定例
遅延時間の平均(粒度300なので5分)が50秒を超えるとWARNING、100秒を超えるとCRITICALを検知するには以下のように設定します。
■ 監視設定例

正常に監視が出来ると以下の画像のようにステータス情報欄に「空きメモリ: ○ MB」(○は数字)が表示されます。

23.5.20. RDS バイナリログデータ量監視
※X-MON3.2で追加されたサービス監視コマンドになります。
監視グループ |
チェックコマンド |
|---|---|
AWS RDS |
AWS/RDS バイナリログデータ量監視 |
RDSインスタンスのバイナリログが占有するディスク領域量を監視します。CloudWatchで確認できるMetric/BinLogDiskUsageの値で、指定した粒度での平均値が取得されます。
以下、対応表です。
MySQL |
MariaDB |
PostgreSQL |
Amazon Aurora |
Oracle |
MSSQL |
|---|---|---|---|---|---|
○ |
○ |
× |
○ |
× |
× |
※PostgresSQLではログファイル数を指定して削除するため監視できません。
・監視設定例
バイナリログデータ量の平均(粒度300なので5分)が500000000を超えるとWARNING、600000000を超えるとCRITICALを検知するには以下のように設定します。
■ 監視設定例

正常に監視が出来ると以下の画像のようにステータス情報欄に「バイナリログデータ量: ○ Byte.」(○は数字)が表示されます。

23.6. AWS S3監視
本章ではAWSで使用出来るS3の監視方法について解説します。ホストの登録方法は ホストの登録方法 をご参照ください。
本章ではホスト名を「X-MON-Ref-S3」で登録します。
23.6.1. 共通警告パターン
S3監視ではCRITICAL、WARNING、UNKNOWNが警告パターンとなっております。
ステータス |
内容 |
|---|---|
CRITICAL |
・APIのリクエストが送信できなかった場合
・データの取得に失敗した場合
・CRITICALのしきい値判定の結果
|
WARNING |
・WARNINGのしきい値判定の結果 |
UNKNOWN |
・APIのデータ通信は成功しているが、適切な値が取得できなかった場合 |
また、監視設定前に
を先にご確認ください。
23.6.2. S3 バケット使用量監視
※X-MON3.2で追加されたサービス監視コマンドになります。
監視グループ |
チェックコマンド |
|---|---|
AWS S3 |
AWS/S3 バケット使用量監視 |
対象バケットの使用しているストレージ量を監視します。
CloudWatchで確認できるMetric/BucketSizeBytesより、前日1日分の最大値を取得します。
・監視設定例
バケット使用量が1GByteを超えるとWARNING、2GByteを超えるとCRITICALを検知するようにするには以下のように設定します。
■ 監視設定例
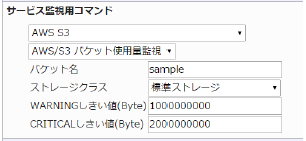
正常に監視が出来ると以下の画像のようにステータス情報欄に「バケット使用量: ○○Byte」(○は数字)が表示されます。

23.6.3. S3 オブジェクト数監視
※X-MON3.2で追加されたサービス監視コマンドになります。
監視グループ |
チェックコマンド |
|---|---|
AWS S3 |
AWS/S3 オブジェクト数監視 |
対象バケットの使用しているストレージ量を監視します。
CloudWatchで確認できるMetric/NumberOfObjectsより、前日1日分の最大値を取得します。
・監視設定例
対象バケットのオブジェクト数が100を超えるとWARNING、200を超えるとCRITICALを検知するようにするには以下のように設定します。
■ 監視設定例
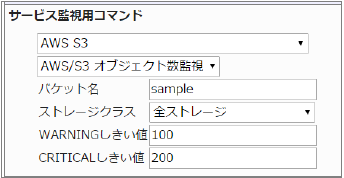
正常に監視が出来ると以下の画像のようにステータス情報欄に「オブジェクト数: ○○count」(○は数字)が表示されます。

23.7. AWSサービス監視
本章ではAWSの課金状態の監視と、カスタムメトリックスの監視方法について解説します。ホストの登録方法は ホストの登録方法 をご参照ください。
本章ではホスト名を「X-MON-Ref-Service」で登録します。
23.7.1. 共通警告パターン
AWSサービス監視ではCRITICAL、WARNING、UNKNOWNが警告パターンとなっております。
ステータス |
内容 |
|---|---|
CRITICAL |
・APIのリクエストが送信できなかった場合
・データの取得に失敗した場合
・CRITICALのしきい値判定の結果
|
WARNING |
・WARNINGのしきい値判定の結果 |
UNKNOWN |
・APIのデータ通信は成功しているが、適切な値が取得できなかった場合 |
また、監視設定前に
を先にご確認ください。
23.7.2. AWSカスタムメトリックス監視
※X-MON3.3で追加されたサービス監視コマンドになります。
監視グループ |
チェックコマンド |
|---|---|
AWS サービス監視 |
AWSカスタムメトリックス監視 |
CloudWatchで確認できる任意のカスタムメトリックスの値を監視します。
※デフォルトでCloudWatchに登録されている、「EBS」「EC2」「RDS」「S3」などに関してはX-MON3.7.0以降指定し、取得することが可能です。
・監視設定例
Linuxシステムのインスタンスにメモリ使用量を取得する設定を入れ、使用量が30%を超えるとWARNING、50%を超えるとCRITICALを検知するように設定します。
Dimension NameとDimension Valueが複数行ある場合はカンマ区切りで設定します。
取得期間の平均値を取得するものとします。
■ Cloudwatchでのメトリクス確認
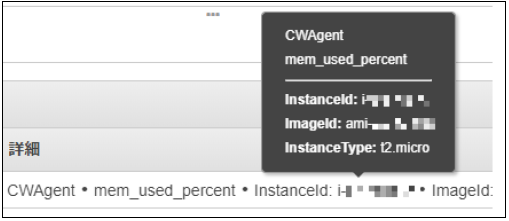
■ 監視設定例
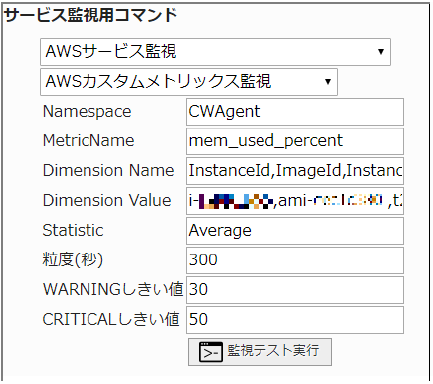
正常に監視が出来ると以下の画像のようにステータス情報欄に「<カスタムメトリックス名>:○○<単位>」(○は数字)が表示されます。

23.7.3. AWS課金監視
※X-MON3.0.9で追加されたサービス監視コマンドになります。
監視グループ |
チェックコマンド |
|---|---|
AWS サービス監視 |
AWS課金監視 |
AWSの課金額を監視します。
CloudWatchで確認できるMetric/Estimated Chargeの値で、4時間毎での最大値を取得します。
・監視設定例
全AWSサービスの課金額が$30を超えるとWARNING、$50を超えるとCRITICALを検知するようにするには以下のように設定します。
■ 監視設定例
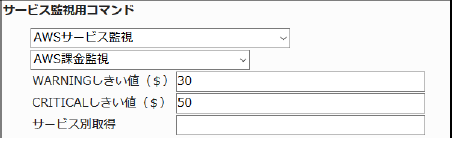
正常に監視が出来ると以下の画像のようにステータス情報欄に「課金額は、$○○です。」(○は数字)が表示されます。

23.7.4. AWS課金監視(一括請求アカウント)
※X-MON3.0.9で追加されたサービス監視コマンドになります。
監視グループ |
チェックコマンド |
|---|---|
AWS サービス監視 |
AWS課金監視(一括請求アカウント) |
アカウントIDごとに課金額を取得した後、各課金額を合算した値で監視を行います。
・監視設定例
全アカウントIDの合計課金額が$1000を超えるとWARNING、$2000を超えるとCRITICALを検知するようにするには以下のように設定します。
■ 監視設定例
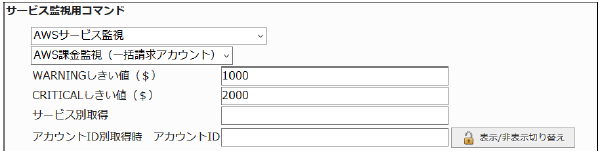
正常に監視が出来ると以下の画像のようにステータス情報欄に「課金額は、$○○です。」(○は数字)が表示されます。

23.8. カスタム監視
X-MONにて搭載されているプラグイン設定以外に、AWSインスタンスを監視する方法について解説します。
使用出来る環境についても記載しておりますので、ご参考ください。
23.8.1. EC2をポート監視、リソース監視をする
EC2インスタンスにおいても、通常の物理サーバのようにポート監視やリソース監視は可能です。
リソース監視ではSNMPやNRPEをインスタンスにインストールしてご使用ください。
ポート監視と共通ですが、インスタンスへのアクセス制御を行う「SecurityGroup」にて対象のポートを設定するようにしてください。
HTTPの場合はTCP:80番など、リソースのエージェントのSNMPの場合はUDP:161番、NRPEはTCP:5666番となります。
23.8.2. ELBのHTTPを監視する
ELBにてHTTPを負荷分散している場合に使用出来ます。
2013年6月現在、ELBに対しては固定グローバルIPが設定出来ません。
X-MON3.0.8以降では、ELBのFQDNでホストの登録が出来るようになりましたので、こちらの方法を使用する必要はございません。
X-MON3.0.7以前の場合は、ELBのグローバルに対してHTTP監視をする場合は独自のプラグイン設定にて監視プラグインを作成して監視を行います。
ELBに対して独自ドメインを設定する方法として、CNAMEを使用する方法、もしくはAmazon Route53にて「Zone Apex」を使用する方法があります。
詳細は https://aws.amazon.com/jp/route53/faqs/#Zone_apex をご参照ください。
また、本章の独自監視プラグインの作成については別途高度監視リファレンスもご参照ください。
・独自監視プラグインの作成
[高度な設定] - [監視プラグイン設定]にて作成します。
登録をクリックします。
新規登録画面となります。
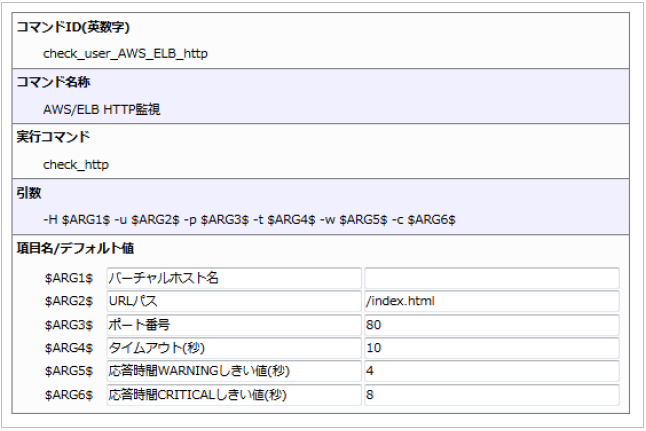
設定例を記載しておりますので、その通り記入してください。
設定例
項目 |
内容 |
|---|---|
コマンドID(英数字) |
AWS_ELB_http |
コマンド名称 |
AWS/ELB HTTP監視 |
コマンドタイプ |
サービス用コマンド |
コマンドグループ |
AWS ELB |
実行コマンド |
check_http |
引数 |
-H $ARG1$ -u $ARG2$ -p $ARG3$ -t $ARG4$ -w $ARG5$ -c $ARG6$ |
■ 入力
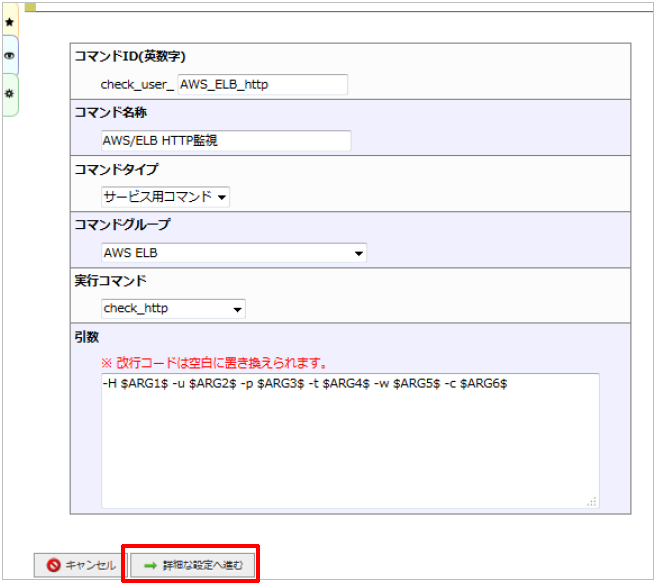
入力が出来たら「詳細な設定へ進む」をクリックします。
引数に対する入力設定(監視設定時に表示される項目名やデフォルト値)を設定しますので下記表の通りに設定します。
引数 |
項目名 |
デフォルト値 |
|---|---|---|
$ARG1$ |
バーチャルホスト名 |
(入力なし) |
$ARG2$ |
URLパス |
/index.html |
$ARG3$ |
ポート番号 |
80 |
$ARG4$ |
タイムアウト(秒) |
10 |
$ARG5$ |
応答時間WARNINGしきい値(秒) |
4 |
$ARG6$ |
応答時間CRITICALしきい値(秒) |
8 |
■ 入力
入力が出来たら「作成と承認」をクリックして完了してください。
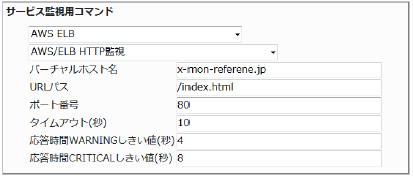
・監視設定例
また、URLパスも必要に応じ、 index.php など任意のものに変更してください。
■ 監視設定例
正常に監視が出来ると、ステータス欄に「HTTP:OK~」が表示されます。

これでELBに対するドメイン名を用いたHTTP監視が出来るようになりました。
23.8.3. RDSの接続監視を行う
EC2からRDSへの接続確認をする事で、データベースが正常に応答しているかを確認出来ます。
本章ではEC2はAmazonLinuxAMIを使用し、RDSはMySQLを使用しています。
また、EC2インスタンスは固定グローバルIPアドレス (Elastic IP) が設定されている必要があります。そのElastic IPを、X-MONにホスト登録してください。
接続確認を行う方法として、NRPEエージェントを使用する方法とHTTPの文字列監視を使用する方法があります。
また、共通の手順としてMySQLに監視用の権限の低いユーザを作成します。
本章では、下記の情報を例で作成します。
項目 |
内容 |
|---|---|
ユーザ名 |
kanshi_user |
パスワード |
kanshi_pass |
権限 |
USAGE |
データベース |
指定なし(information_schemaのみに与えられます) |
■ MySQLユーザの作成(RDSへ接続後)
mysql> grant USAGE on *.* to kanshi_user@'%' identified by 'kanshi_pass';
Query OK, 0 rows affected (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
|
作成が出来たら、EC2インスタンスから接続確認を行います。
$ mysql -u kanshi_user -p -h <RDSインスタンスのEndPointURL>
Enter password:<パスワードを入力>
~中略~
mysql> exit
Bye
|
接続確認が出来れば、ユーザの作成は完了です。
23.8.3.1. NRPEを使用する
NRPEを使用する場合は事前に、EC2インスタンスにNRPEとNagiosPluginをインストールする必要があります。
インストール方法は別途マニュアル「NRPE導入マニュアル」をご参照ください。
EC2インスタンスへはソースからのインストールとなります。
また、mysql-libsはすでにEC2インスタンスにmysql5.5用がインストールされております。
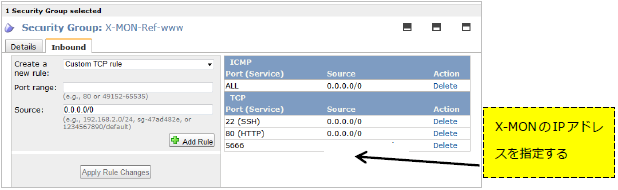
その他、SecurityGroupの設定でX-MONからTCP/5666番の接続を許可してください。
監視プラグインにて、接続確認を行います。使用する監視プラグインは「check_mysql」となります。ソースからインストールした場合は
/usr/local/nagios/libexec/check_mysql
となります。
■ 発行例(EC2インスタンス上)
$ /usr/local/nagios/libexec/check_mysql -H <RDSのEndPointURL> -u kanshi_user -p kanshi_pass |
Uptime: 1934 Threads: 2 Questions: 948 Slow queries: 0 Opens: 223 Flush tables: 1 Open tables: 41 Queries per second avg: 0.490
正常に発行されると、MySQLの情報が表示されます。
・監視設定例
監視グループ |
チェックコマンド |
|---|---|
データベース監視 |
NRPE経由でのMySQL監視 |
EC2インスタンス上からRDSへcheck_mysqlプラグインにて確認が出来れば、X-MONにて監視登録を行います。
監視登録をするのはElasticIPのIPアドレスでホスト登録したEC2インスタンスです。
本章の例でのユーザでは以下のように設定します。
項目 |
内容 |
|---|---|
対象ホスト名またはIPアドレス |
RDSのEndPointURLを入力します。 |
データベース名 |
information_schema |
ポート番号 |
3306(デフォルト) |
ユーザ名 |
kanshi_user |
パスワード |
kanshi_pass |
NRPEタイムアウト |
15(デフォルト) |
■ 監視設定例
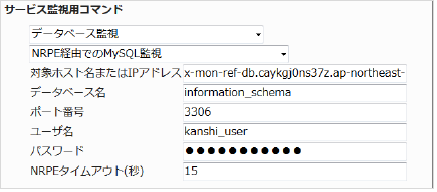
正常に監視が出来ると下記画像のようにステータス欄にデータベースの情報が表示されます。
■ 正常時

データベースにアクセス出来ない場合は下記画像のようにCRITICALを検知します。
■ 検知時 (監視設定でパスワードを意図的に違うものに変更しています)

これでNRPEを使用したRDSへの接続確認の設定は完了です。
23.8.3.2. HTTPを使用する
HTTPを使用する際は、データベースへの接続情報を記載したphpファイルへアクセスし、データベースへ接続が成功していたら「MYSQL への接続に成功しました」と表示し、失敗したら「MYSQL への接続に失敗しました」と表示するようにします。
この表示の文字列に対して、文字列監視を行い、RDSへの接続監視を行う形となります。
■ 左)接続成功時 右)接続失敗時
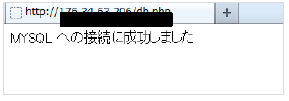
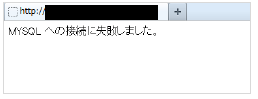
HTTPを使用する場合、php、php-mysqlのインストールが必要です。また、apacheを使用している事が条件となります。
・サンプルプログラム
phpのサンプルプログラムを記載します。ご参考ください。
セキュリティ面を考慮し、実際の運用ではRDSへの接続情報は別ファイルからインクルードする方法をお勧めします。
ファイル名はdb.phpとします。
<?php
$hostname = "<RDSへのEndPointURL>"; //RDSの情報
$uname = "kanshi_user"; //接続ユーザ名
$upass = "kanshi_pass"; //接続パスワード
if( !$res_dbcon = mysql_connect( $hostname, $uname, $upass) ){
echo "MYSQL への接続に失敗しました。";
exit;
}
echo "MYSQL への接続に成功しました";
mysql_close( $res_dbcon );
?>
|
ファイルを作成したら、ドキュメントルートへ保存してください。
・監視設定例
監視グループ |
チェックコマンド |
|---|---|
Webサービス監視 |
HTTP監視 |
プログラムが用意出来れば監視設定を行います。
X-MONにて監視登録を行います。監視登録をするのはElasticIPのIPアドレスでホスト登録したEC2インスタンスです。
本章の例では以下のように設定します。
項目 |
内容 |
|---|---|
URLパス |
/db.php |
検出文字列 |
成功 |
その他の設定 |
デフォルトのまま変更なし |
■ 監視設定例
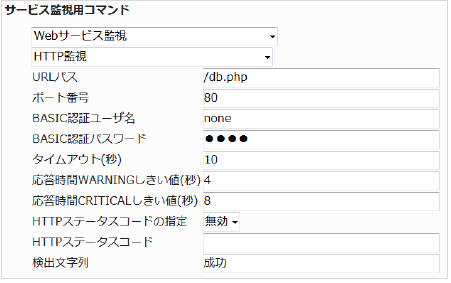
正常に監視が出来れば下記画像のようにOKが検知されます。
■ 正常時

RDSへ接続出来ない場合は下記画像のように「pattern not found」とステータス欄に表示されます。
■ 検知時(db.phpにて意図的にパスワードを違う物に変更しています)

これでEC2インスタンスからRDSへHTTPを使った接続確認が出来るようになりました。
23.8.4. RDSのフェールオーバー監視を行う
RDSをMultiAZで使用している場合、フェールオーバーして別のAvailability Zoneにて稼働し始めた(フェールオーバー)した事を監視する事が出来ます。
監視するには、EC2インスタンスに固定グローバルIPアドレス(Elastic IP)が設定されている必要があります。Elastic IPをX-MONにホスト登録してください。
また、NRPEのインストールおよび接続設定、X-MONにて独自監視プラグインの作成が必要となります。
監視する方法としては、RDSのEndPointURLをEC2インスタンス上で名前解決を行い、事前に調べておいたIPアドレスから変更がないかを確認するというものになります。
フェールオーバーした場合はIPアドレスが変更されますので、IPアドレスの変更を検知した時はフェールオーバーした時、となります。
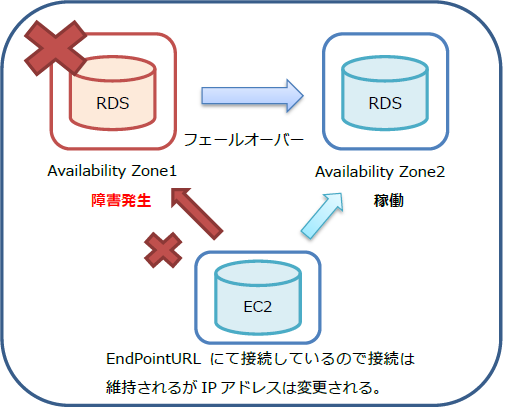
RDSがフェールオーバーするのは2013年6月現在
プライマリ利用可能ゾーンの可用性損失
プライマリに対するネットワーク接続の喪失
プライマリ上でのコンピュートユニット障害
プライマリへのストレージ不良
となっております。情報は都度更新されますので、RDSの公式情報をご確認ください。
http://aws.amazon.com/jp/rds/faqs/#43
23.8.4.1. 事前準備
EC2インスタンスにNRPEとNagiosPluginをインストールする必要があります。インストール方法は別途マニュアル「NRPE導入マニュアル」をご参照ください。
EC2インスタンスへはソースからのインストールとなります。
また、mysql-libsはすでにEC2インスタンスにmysql5.5用がインストールされております。
その他、SecurityGroupの設定でX-MONからTCP/5666番の接続を許可してください。
監視プラグインにて、接続確認を行います。使用する監視プラグインは「check_dns」となります。ソースからインストールした場合は
RDSのIPアドレスも確認しておきます。
EC2インスタンス上で名前解決を行い、IPアドレスを控えておきます。
EndPointURLが「x-mon-ref-db.caykgj0ns37z.ap-northeast-1.rds.amazonaws.com」の場合、下記コマンドで確認します。
$ dig x-mon-ref-db.caykgj0ns37z.ap-northeast-1.rds.amazonaws.com |
~中略~
;; ANSWER SECTION:
x-mon-ref-db.caykgj0ns37z.ap-northeast-1.rds.amazonaws.com. 60 IN CNAME ec2-54-248-175-2.ap-northeast-1.compute.amazonaws.com.
ec2-54-248-175-2.ap-northeast-1.compute.amazonaws.com. 60 IN A 10.132.202.56
~中略~
本章の例ではこの「10.132.202.56」を例に使用します。
check_dnsプラグインをコマンドで発行して確かめてみます。
コマンドが長くなりますので「\」を使用して改行しています。
$ /usr/local/nagios/libexec/check_dns \
> -H x-mon-ref-db.caykgj0ns37z.ap-northeast-1.rds.amazonaws.com \
> -a 10.132.202.56
DNS OK: 0.011 seconds response time.~後略~
|
-H の後にEndPoointURLを指定し、-aはIPアドレスを指定します。
正常なのでOKが返ってきます。
これを、IPアドレスを意図的に間違えて発行します。
$ /usr/local/nagios/libexec/check_dns \
> -H x-mon-ref-db.caykgj0ns37z.ap-northeast-1.rds.amazonaws.com \
> -a 10.132.202.57
DNS CRITICAL - expected '10.132.202.57' but got '10.132.202.56'
|
CRITICALが応答されました。名前解決の結果と期待するIPアドレスが違うためです。
フェールオーバーしている際はこれが検知されます。
23.8.4.2. NRPEの設定
事前準備が出来たらNRPEにてcheck_dnsを使用出来るように設定します。
ソースからのインストールの場合、NRPEの設定ファイルは「/usr/local/nagios/etc/nrpe.cfg」となります。
まずはバックアップを取得します。
$ sudo cp -i /usr/local/nagios/etc/nrpc.cfg /usr/local/nagios/etc/nrpe.cfg.YYYYMMDD |
バックアップするファイル名は適宜変更してください。
設定ファイルを編集します。
$ sudo vi /usr/local/nagios/etc/nrpc.cfg |
下2行をファイルの最下部へ追加し、「:wq」で保存して編集を終えてください。
#dns
command[check_dns]=/usr/local/nagios/libexec/check_dns $ARG1$
|
NRPEサービスを再起動して反映させます。
$ sudo service nrpe restart
Shutting down nrpe: [ OK ]
Starting nrpe: [ OK ]
|
これで設定は完了です。
23.8.4.3. 独自監視プラグインの作成
本監視用の監視プラグインはデフォルトでは搭載していないため、独自監視プラグインを作成します。
[高度な設定] - [監視プラグイン設定]にて作成します。
登録をクリックします。
新規登録画面となります。
設定例を記載しておりますので、その通り記入してください。
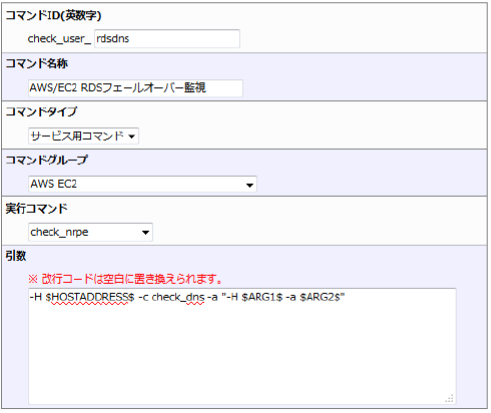
項目 |
内容 |
|---|---|
コマンドID(英数字) |
rdsdns |
コマンド名称 |
AWS/EC2 RDSフェールオーバー監視 |
コマンドタイプ |
サービス用コマンド |
コマンドグループ |
AWS EC2 |
実行コマンド |
check_nrpe |
引数 |
-H $HOSTADDRESS$ -c check_dns -a "-H $ARG1$ -a $ARG2$" |
$HOSTADDRESS$ はNagiosマクロ変数となっており、X-MONでホスト登録した際のIPアドレスが指定されます。
その他引数の$ARG{num}$はX-MONマクロ変数となっております。
入力が出来たら「詳細な設定へ進む」をクリックします。
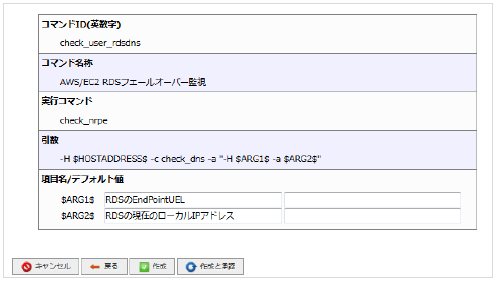
引数に対する入力設定(監視設定時に表示される項目名やデフォルト値)を設定しますので下記表の通りに設定します。
引数 |
項目名 |
デフォルト値 |
|---|---|---|
$ARG1$ |
RDSのEndPointUEL |
(入力なし) |
$ARG2$ |
RDSの現在のローカルIPアドレス |
(入力なし) |
■ 入力
■ 詳細設定
入力が出来たら「作成と承認」をクリックして完了してください。
一覧の画面に戻ると、作成したプラグインが追加されます。
このプラグイン設定を用いて監視設定を行います。
■ 監視プラグイン設定一覧
23.8.4.4. 監視設定例
作成した「AWS/EC2 RDSフェールオーバー監視」を使用します。
RDSのEndPointURLと現在のローカルIPアドレスを入力します。
■ 監視設定例
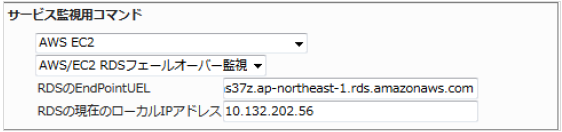
正常に監視が出来ると下記画像のようにOKを検知し、ステータス情報欄には名前解決の結果が記載されます。
■ 正常時

23.8.4.5. フェールオーバーを確認する
実際にフェールオーバーを実施し、検知するか確認します。
 運用中の環境ではサービスに影響が出る可能性がありますので充分注意して実施してください。また、自動フェールバックはしませんので、元に戻すには同じ作業をもう一度実施してください。
運用中の環境ではサービスに影響が出る可能性がありますので充分注意して実施してください。また、自動フェールバックはしませんので、元に戻すには同じ作業をもう一度実施してください。
作業はAWSのマネージメントコンソールにて行います。
RDS ダッシュボード画面を開き、対象のインスタンスの情報を表示します。
「Availability Zone」で現在の設定を確認します。
本章の例では「ap-northeast-1a」となっています。
■ RDS
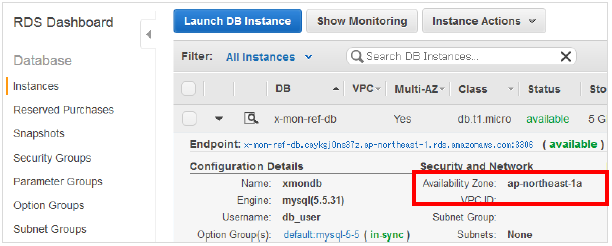
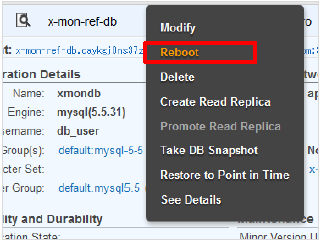
確認が出来たら対象のインスタンスを右クリックし、「Reboot」をクリックします。
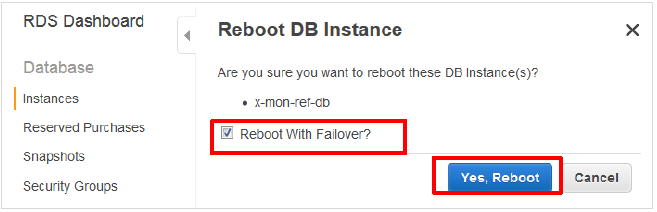
Rebootの確認画面が表示されますので、「Reboot With Failover?」にチェックを入れて、「Yes, Reboot」をクリックしてください。
インスタンス一覧画面に戻ります。Statusが「rebooting」となりますので、完了するまで待ちます。

完了すると「available」となります。
■ Reboot後

「Availability Zone」を確認すると、「ap-northeast-1c」とReboot前から変更されました。
■ RDS
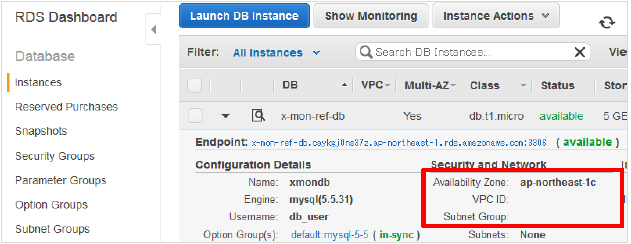
再起動後、「Availability Zone」の情報が更新される前時間がかかる場合があります。

これで正常にフェールオーバー時に検知できる事が確認出来ました。
復旧させるには、監視の値が変更されているので、現在のIPアドレスを確認して、サービスの編集にて、現在のIPアドレスを変更してください。
また、フェールオーバーに関してはRDSの[Events]からも確認出来ます。
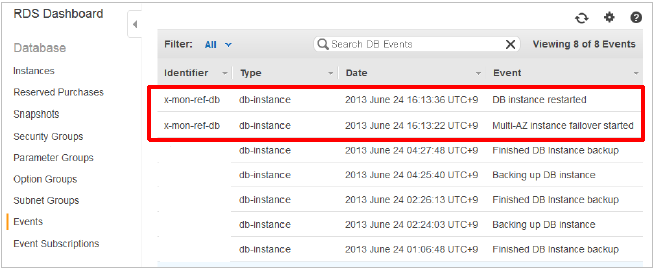
検知した際は、こちらもご確認頂けますようお願いします。
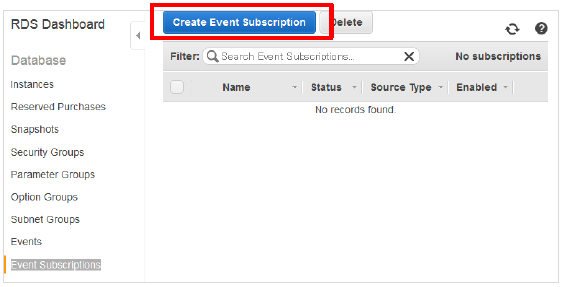
23.8.4.6. Event Subscriptionsを使用する
RDSの機能でEvent Subscriptionsという機能があります。
これはRDSでイベントが発生した際にSimple Notification Service (SNS)と連動して、メール通知が行われる機能です。
この機能の中にもフェールオーバー発生時にメール通知を行う機能があります。
X-MONでの監視に加えて、こちらも設定して頂くとより迅速に障害対応が出来るようになるでしょう。
参考:http://aws.amazon.com/jp/rds/faqs/#44
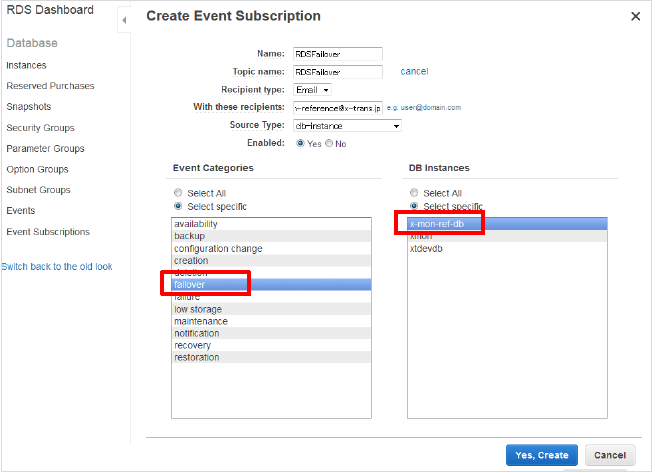
NameとTopic Nameは任意の物を入力します。
[Recipient type]は「Email」を指定し、[With these recipients]に通知先アドレスを記入します。その後はトリガーとなる対象と動作を指定します。
今回は[Source Type]は「db-instance」を選択し、[Event Categories]から「failover」、[DB Instances]から任意のDBインスタンスを指定します。
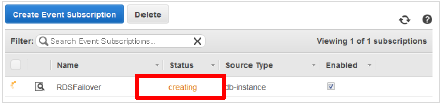
また、指定した通知先のアドレスにメールが届きますので、リンクをクリックしてブラウザで認証を行います。
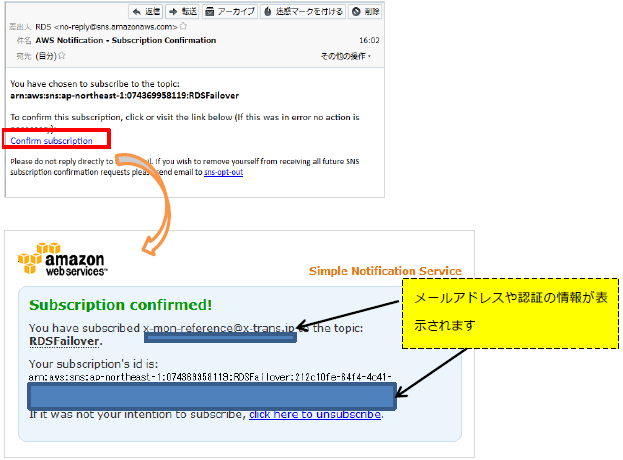
認証が終了すると、メールが届きます。
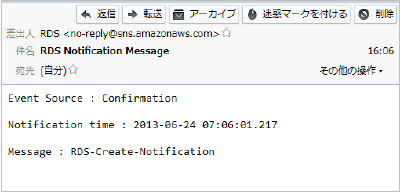
作成が完了すると、下記のようにStatusが「active」となります。
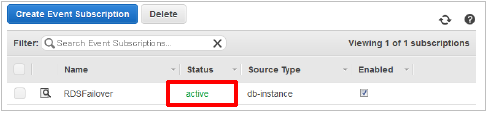
EventSubscriptionsが有効な状態でフェールオーバーを実施した場合は下記のようなメールが届きます。
■ フェールオーバー開始
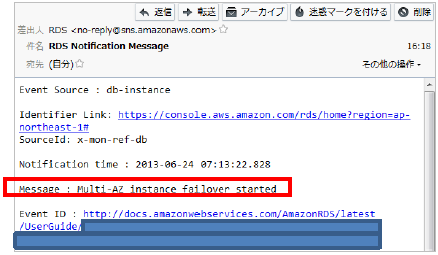
フェールオーバーが完了した際もメール通知がされます。
■ フェールオーバー完了
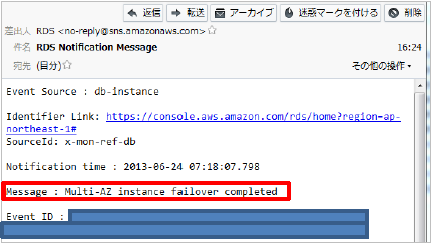
設定方法やメール内容は予告なく変更となる場合がありますので、最新情報をご確認ください。